nwj2010
- жөҸи§Ҳ: 89484 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: е®Ғжіў
-

ж–Үз« еҲҶзұ»
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2011-05 ( 1)
- 2011-01 ( 1)
- 2010-12 ( 17)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
836969871пјҡ
[color=red][size=x-small][align ...
WebOfficeжҺ§д»¶зҡ„дҪҝз”ЁпјҲдёҖпјү -
chen123.comпјҡ
еҗҢжұӮпјҢйӮ®з®ұ2659621527@qq.com
ж“ҚдҪң WebOffice.ocx д»Јз ҒйӣҶеҗҲ -
huangfenghitпјҡ
еҸ—з”ЁдәҶгҖӮеҜ№дәҺ3.0дёӯжІЎжңүhitsжҲ‘йғҒй—·дәҶеҫҲд№…гҖӮ
Lucene3.0 demo -
01jiangwei01пјҡ
дҪ еҘҪпјҢиғҪдёҚиғҪз»ҷжҲ‘еҸ‘дёҖд»ҪhtmlеүҚз«ҜпјҢjsp,javaжңҚеҠЎеҷЁж®өдҝқ ...
ж“ҚдҪң WebOffice.ocx д»Јз ҒйӣҶеҗҲ
Googleзҡ„ејҖе§ӢпјҚпјҚеү–жһҗеӨ§и§„жЁЎи¶…ж–Үжң¬зҪ‘з»ңжҗңзҙўеј•ж“Һ
иҪ¬иҪҪиҮӘпјҡhttp://www.yeeyan.com/articles/view/thunder/364
еҺҹдҪңиҖ…: Sergey Brin and Lawrence PageиҜ‘иҖ…: йӣ·еЈ°еӨ§йӣЁзӮ№еӨ§ (Blog)
иҜ‘иҖ…пјҡжң¬ж–ҮжҳҜи°·жӯҢеҲӣе§ӢдәәSergeyе’ҢLarryеңЁж–ҜеқҰзҰҸеӨ§еӯҰи®Ўз®—жңәзі»иҜ»еҚҡеЈ«ж—¶зҡ„дёҖзҜҮи®әж–ҮгҖӮеҸ‘иЎЁдәҺ1997е№ҙгҖӮGoogleзҡ„дёҖеҲҮеә”иҜҘйғҪиө·жәҗдёҺжӯӨгҖӮж·ұе…ҘдәҶи§ЈGoogleпјҢж·ұе…ҘдәҶи§Јдә’иҒ”зҪ‘зҡ„жңӘжқҘпјҢеҪ“иҜ»жӯӨж–ҮгҖӮжҲ‘жҠҠе…Ёж–ҮеҲҶжҲҗ6дёӘйғЁеҲҶпјҢжҺЁиҚҗеҲ°иҝҷйҮҢгҖӮжңүе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘдёҖиө·жқҘзҝ»иҜ‘гҖӮ
жҲ‘жІЎжңүеҸ‘зҺ°жң¬ж–Үзҡ„е®Ңж•ҙдёӯиҜ‘пјҢеҸӘжүҫеҲ°дәҶиҝҷдёӘзүҮж®өпјҢз”ұxfygxжңӢеҸӢзҝ»иҜ‘дәҶжң¬ж–Үзҡ„第дёҖйғЁеҲҶпјҢе…¶д»–дјјд№ҺжІЎжңүе…ЁйғЁе®ҢжҲҗгҖӮ
жүҖд»ҘпјҢиҝҷйғЁеҲҶиҜ‘ж–ҮжҳҜxfygxеҺҹдҪңпјҢиҖҢйқһжҲ‘зҡ„зҝ»иҜ‘пјҒжҲ‘еҸӘжҳҜе°ұиҮӘе·ұзҡ„зҗҶи§ЈеҒҡдәҶдәӣж”№еҠЁгҖӮеҰӮжһңжңүе№ёxfygxжңӢеҸӢиғҪзңӢеҲ°жҲ‘еңЁд»–/еҘ№еҚҡе®ўзҡ„з•ҷиЁҖпјҢжқҘжҲ‘们иҜ‘иЁҖпјҢжҲ‘йқһеёёеёҢжңӣиғҪжҠҠжң¬ж–ҮиҪ¬еҲ°д»–/еҘ№еҗҚдёӢгҖӮ
еҸҰеӨ–пјҢеҰӮжһңжӮЁеҸ‘зҺ°е·Іжңүе…¶д»–еҮәиүІзҡ„е®Ңж•ҙдёӯиҜ‘зүҲдәҶпјҢиҜ·е‘ҠиҜүжҲ‘们гҖӮе…Қеҫ—иҜ‘иҖ…们йҮҚеӨҚеҠіеҠЁгҖӮ
ж‘ҳиҰҒ
еңЁжң¬ж–ҮдёӯпјҢжҲ‘们е°Ҷд»Ӣз»ҚGoogleпјҢдёҖдёӘе……еҲҶеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件пјҲиҜ‘иҖ…пјҡеҚіHTMLж–Ү件пјүз»“жһ„иҝӣиЎҢжҗңзҙўзҡ„еӨ§и§„жЁЎжҗңзҙўеј•ж“Һзҡ„еҺҹеһӢгҖӮGoogleеҸҜд»Ҙжңүж•Ҳең°еҜ№дә’иҒ”зҪ‘пјҲWebпјүиө„жәҗиҝӣиЎҢзҲ¬иЎҢжҗңзҙўпјҲcrawlпјүгҖ”жіЁ 1гҖ•е’Ңзҙўеј•пјҢжҜ”зӣ®еүҚе·Із»ҸеӯҳеңЁзҡ„зі»з»ҹжңүжӣҙд»Өдәәж»Ўж„Ҹзҡ„жҗңзҙўз»“жһңгҖӮиҜҘеҺҹеһӢзҡ„ж•°жҚ®еә“еҢ…жӢ¬2400дёҮйЎөйқўзҡ„е…Ёж–Үе’Ңд№Ӣй—ҙзҡ„й“ҫжҺҘпјҢеҸҜйҖҡиҝҮhttp://google.stanford.edu/и®ҝй—®гҖӮ
и®ҫи®Ўжҗңзҙўеј•ж“ҺжҳҜдёҖйЎ№еҜҢжңүжҢ‘жҲҳзҡ„д»»еҠЎгҖӮжҗңзҙўеј•ж“Һдёәж•°д»Ҙдәҝи®Ўзҡ„зҪ‘йЎөе»әз«Ӣзҙўеј•пјҢиҖҢиҝҷдәӣзҪ‘йЎөеҢ…еҗ«дәҶеҗҢж ·ж•°йҮҸзә§зҡ„дёҚеҗҢиҜҚиҜӯгҖӮжҜҸеӨ©е“Қеә”ж•°еҚғдёҮи®Ўзҡ„жҹҘиҜўиҜ·жұӮгҖӮе°Ҫз®ЎеӨ§и§„жЁЎзҪ‘з»ңжҗңзҙўеј•ж“ҺжҳҜеҫҲйҮҚиҰҒзҡ„пјҢдҪҶеңЁиҝҷдёӘйўҶеҹҹеҫҲе°‘жңүзҗҶи®әз ”з©¶гҖӮжӣҙз”ұдәҺжҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•е’Ңдә’иҒ”зҪ‘зҡ„жҷ®еҸҠпјҢд»ҠеӨ©иҝҷж ·зҡ„жҗңзҙўеј•ж“Һе’Ңдёүе№ҙеүҚзҡ„жҗңзҙўеј•ж“ҺдјҡжҳҜйқһеёёдёҚеҗҢзҡ„гҖӮжң¬ж–ҮеҜ№жҲ‘们зҡ„еӨ§и§„жЁЎжҗңзҙўеј•ж“ҺиҝӣиЎҢдәҶж·ұе…Ҙзҡ„и®Ёи®әпјҢиҝҷд№ҹжҳҜзӣ®еүҚдёәжӯўжҲ‘们жүҖзҹҘйҒ“зҡ„е…¬ејҖеҸ‘иЎЁзҡ„第дёҖзҜҮеҰӮжӯӨиҜҰз»Ҷзҡ„и®Ёи®әгҖӮ
йҷӨдәҶеҰӮдҪ•жҠҠдј з»ҹзҡ„жҗңзҙўжҠҖжңҜжү©еұ•еҲ°еүҚжүҖжңӘжңүзҡ„жө·йҮҸж•°жҚ®пјҢжҲ‘们иҝҳйқўдёҙиҝҷж ·дёҖдёӘж–°зҡ„жҠҖжңҜжҢ‘жҲҳпјҡеҰӮдҪ•дҪҝз”Ёи¶…ж–Үжң¬ж–Ү件жүҖи•ҙеҗ«зҡ„жү©еұ•дҝЎжҒҜд»Ҙдә§з”ҹжӣҙеҘҪзҡ„жҗңзҙўз»“жһңгҖӮжң¬ж–Үи®Ёи®әдәҶеҰӮдҪ•е»әз«ӢдёҖдёӘе®һз”Ёзҡ„еӨ§и§„жЁЎзі»з»ҹпјҢд»ҘеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件дёӯзҡ„йўқеӨ–дҝЎжҒҜгҖӮеҸҰеӨ–пјҢжҲ‘们д№ҹе…іжіЁдәҶеҰӮдҪ•жңүж•ҲеӨ„зҗҶи¶…ж–Үжң¬ж–Ү件дёҚеҸҜжҺ§зҡ„й—®йўҳпјҢеӣ дёәдәә们еҸҜд»ҘйҡҸж„ҸеҸ‘иЎЁи¶…ж–Ү жң¬ж–Ү件пјҲиҜ‘иҖ…пјҡеҰӮдёӘдәәзҪ‘йЎөпјүгҖӮ
е…ій”®иҜҚ
World Wide Web, Search Engines, Information retrieval, PageRank, Google
1.з®Җд»Ӣ
дә’иҒ”зҪ‘еҜ№дҝЎжҒҜжЈҖзҙўпјҲInformation RetrievalпјүйўҶеҹҹдә§з”ҹдәҶж–°зҡ„жҢ‘жҲҳгҖӮзҪ‘дёҠзҡ„дҝЎжҒҜж•°йҮҸжҳҜеңЁдёҚж–ӯзҡ„еҝ«йҖҹеўһй•ҝпјҢеҗҢж—¶жңүи¶ҠжқҘи¶ҠеӨҡеҜ№зҪ‘з»ңжҗңзҙўжҜ«ж— з»ҸйӘҢзҡ„ж–°з”ЁжҲ·дёҠзҪ‘гҖӮеңЁзҪ‘дёҠеҶІжөӘж—¶пјҢдәә们дёҖиҲ¬дјҡеҲ©з”ЁзҪ‘з»ңзҡ„вҖңй“ҫжҺҘеӣҫвҖқпјҲиҜ‘иҖ…пјҡжғіеғҸжҜҸдёӘзҪ‘йЎөжҳҜдёҖдёӘзӮ№пјҢзҪ‘йЎөд№Ӣй—ҙзҡ„й“ҫжҺҘжҳҜд»ҺдёҖдёӘзӮ№жҢҮеҗ‘еҸҰдёҖдёӘзӮ№зҡ„иҫ№пјҢиҝҷе°ұжһ„жҲҗдәҶдёҖеј жңүеҗ‘еӣҫгҖӮпјүгҖӮиҖҢиҝҷз»Ҹеёёд»ҺдёҖдёӘдәәе·Ҙз»ҙжҠӨзҡ„зҪ‘еқҖеҲ—иЎЁпјҲеҰӮYahoo!пјүжҲ–жҳҜдёҖдёӘжҗңзҙўеј•ж“ҺејҖе§ӢгҖӮдәәе·Ҙз»ҙжҠӨзҡ„еҲ—иЎЁжңүж•ҲиҰҶзӣ–дәҶжөҒиЎҢзҡ„дё»йўҳпјҢдҪҶиҝҷдәӣжҳҜдё»и§Ӯзҡ„пјҢиҠұиҙ№й«ҳжҳӮпјҢжӣҙж–°зј“ж…ўпјҢ并且дёҚиғҪиҰҶзӣ–е…ЁйғЁзҡ„дё»йўҳпјҢзү№еҲ«жҳҜеҶ·еғ»зҡ„дё»йўҳгҖӮдҫқиө–е…ій”®иҜҚеҢ№й…Қзҡ„иҮӘеҠЁжҗңзҙўеј•ж“ҺйҖҡеёёиҝ”еӣһеӨӘеӨҡзҡ„дҪҺиҙЁйҮҸзҡ„еҢ№й…Қз»“жһңгҖӮжӣҙзіҹзҡ„жҳҜпјҢдёҖдәӣе№ҝе‘Ҡе•ҶйҖҡиҝҮжҹҗдәӣж–№ејҸиҜҜеҜјжҗңзҙўеј•ж“Һд»ҘиҜ•еӣҫеҗёеј•дәә们зҡ„жіЁж„ҸеҠӣгҖӮжҲ‘们е»әз«ӢдәҶдёҖдёӘеӨ§и§„жЁЎжҗңзҙўеј•ж“ҺжқҘи§ЈеҶіе·ІеӯҳеңЁзі»з»ҹзҡ„и®ёеӨҡй—®йўҳгҖӮе®ғе……еҲҶеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件жүҖиЎЁиҫҫйўқеӨ–дҝЎжҒҜжқҘжҸҗдҫӣжӣҙй«ҳиҙЁйҮҸзҡ„жҗңзҙўз»“жһңгҖӮжҲ‘们йҖүжӢ©иҝҷдёӘеҗҚеӯ—пјҢGoogleпјҢжҳҜеӣ дёәе®ғжҳҜgoogolпјҲиЎЁзӨә10зҡ„100ж¬Ўж–№)иҝҷдёӘиҜҚзҡ„еёёз”ЁжӢјеҶҷжі•гҖӮиҖҢиҝҷдёӘиҜҚзҡ„ж„Ҹд№үдёҺжҲ‘们е»әз«ӢиҝҷдёӘеӨ§и§„жЁЎжҗңзҙўеј•ж“Һзҡ„зӣ®ж ҮжҳҜйқһеёёдёҖиҮҙзҡ„гҖӮ
1.1 дә’иҒ”зҪ‘жҗңзҙўеј•ж“Һ -- жү©еұ•пјҡ1994 - 2000
жҗңзҙўеј•ж“ҺжҠҖжңҜеҝ…йЎ»жһҒеӨ§и§„жЁЎең°жү©еұ•жүҚиғҪиө¶дёҠдә’иҒ”зҪ‘зҡ„еҸ‘еұ•жӯҘдјҗгҖӮеңЁ1994е№ҙ,жңҖж—©зҡ„ webжҗңзҙўеј•ж“Һд№ӢдёҖпјҢWorld Wide Web Worm(WWWW) [McBryan 94]е·Із»Ҹзҙўеј•дәҶ11дёҮwebйЎөйқўе’Ңж–ҮжЎЈгҖӮеҲ°дәҶ1997е№ҙзҡ„11жңҲпјҢйЎ¶зә§зҡ„жҗңзҙўеј•ж“ҺеЈ°з§°зҡ„зҙўеј•зҡ„йЎөйқўж•°йҮҸд»Һ2зҷҫдёҮ(WebCrawler) еҲ°10дәҝ(ж №жҚ® Search Engine Watch)гҖӮеҸҜд»ҘжғіеғҸеҲ°2000е№ҙпјҢзҙўеј•е…ЁйғЁзҡ„Webе°ҶйңҖиҰҒеҢ…еҗ«и¶…иҝҮеҚҒдәҝзҡ„ж–ҮжЎЈгҖӮеҗҢж—¶пјҢжҗңзҙўеј•ж“ҺйңҖиҰҒеӨ„зҗҶзҡ„жҹҘиҜўиҜ·жұӮд№ҹдјҡжңүдёҚеҸҜжғіеғҸзҡ„еўһй•ҝгҖӮеңЁ1994е№ҙ 3жңҲеҲ°4жңҲй—ҙпјҢWorld Wide Web Wormе№іеқҮжҜҸеӨ©ж”¶еҲ°1500дёӘжҹҘиҜўгҖӮиҖҢеҲ°дәҶ1997е№ҙзҡ„11жңҲпјҢAltavistaеЈ°з§°гҖҖе®ғе№іеқҮжҜҸеӨ©иҰҒеӨ„зҗҶеӨ§зәҰ2еҚғдёҮзҡ„жҹҘиҜўгҖӮйҡҸзқҖwebзҡ„з”ЁжҲ·е’ҢдҪҝз”Ёжҗңзҙўеј•ж“Һзҡ„иҮӘеҠЁзі»з»ҹж•°йҮҸзҡ„еўһеҠ пјҢеҲ°2000е№ҙпјҢйЎ¶зә§зҡ„жҗңзҙўеј•ж“ҺжҜҸеӨ©е°ҶдјҡйңҖиҰҒеӨ„зҗҶж•°д»Ҙдәҝи®Ўзҡ„жҹҘиҜўгҖӮжҲ‘们зҡ„зі»з»ҹзҡ„зӣ®ж ҮжҳҜи§ЈеҶіиҝҷдәӣз”ұжҗңзҙўеј•ж“ҺеӨ§и§„жЁЎжү©еұ•жүҖеёҰжқҘзҡ„й—®йўҳпјҢеҢ…жӢ¬иҙЁйҮҸе’ҢеҸҜжү©еұ•жҖ§гҖӮ
1.2 Google:дёҺWebеҗҢжӯҘеҸ‘еұ•
еҚідҫҝе»әз«ӢдёҖдёӘйҖӮеә”д»ҠеӨ©дә’иҒ”зҪ‘дҝЎжҒҜйҮҸзҡ„жҗңзҙўеј•ж“Һе·Із»ҸйқўдёҙзқҖи®ёеӨҡзҡ„жҢ‘жҲҳгҖӮжҲ‘们йңҖиҰҒдҪҝз”Ёеҝ«йҖҹзҲ¬иЎҢжҗңзҙўжҠҖжңҜ收йӣҶwebж–Ү档并дҝқжҢҒе®ғ们зҡ„еҸҠж—¶жӣҙж–°пјӣжҲ‘们йңҖиҰҒеҸҜд»Ҙжңүж•ҲеӯҳеӮЁж–ҮжЎЈзҙўеј•е’Ңж–ҮжЎЈиҮӘиә«пјҲиҝҷдёҚжҳҜеҝ…йЎ»зҡ„пјүзҡ„жө·йҮҸеӯҳеӮЁз©әй—ҙпјӣжҲ‘们йңҖиҰҒеҸҜд»Ҙжңүж•ҲеӨ„зҗҶж•°зҷҫGBж•°жҚ®зҡ„зҙўеј•зі»з»ҹпјӣжҲ‘们иҝҳйңҖиҰҒеҸҜд»ҘеңЁдёҖз§’еҶ…еӨ„зҗҶжҲҗзҷҫдёҠеҚғзҡ„жҹҘиҜўзҡ„и®Ўз®—иғҪеҠӣгҖӮ
иҝҷдәӣд»»еҠЎйғҪйҡҸзқҖWebзҡ„еўһй•ҝиҖҢж„ҲеҸ‘еҸҳзҡ„еӣ°йҡҫгҖӮ然иҖҢпјҢ硬件жҖ§иғҪзҡ„жҸҗй«ҳе’Ңиҙ№з”Ёзҡ„йҷҚдҪҺеҸҜд»ҘйғЁеҲҶзҡ„жҠөж¶Ҳиҝҷдәӣеӣ°йҡҫгҖӮдҪҶжҹҗдәӣж–№йқўжҳҜдёӘдҫӢеӨ–пјҢеҰӮзЎ¬зӣҳж•°жҚ®иҜ»еҸ–зҡ„йҖҹеәҰе’Ңж“ҚдҪңзі»з»ҹзҡ„йІҒжЈ’жҖ§пјҲиҜ‘иҖ…пјҡеҸҜд»ҘйҖҡдҝ—ең°зҗҶи§ЈдёәзЁіе®ҡжҖ§пјүйғҪжІЎжңүжҳҫи‘—жҸҗй«ҳгҖӮеңЁи®ҫи®ЎGoogleзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们已з»ҸиҖғиҷ‘еҲ°дәҶWeb е’ҢжҠҖжңҜиҝҷдёӨж–№йқўзҡ„еҸ‘еұ•гҖӮGoogleиў«и®ҫи®ЎдёәеҸҜд»ҘйҖӮеә”жһҒеӨ§ж•°жҚ®йҮҸгҖӮе®ғжңүж•ҲдҪҝз”ЁеӯҳеӮЁз©әй—ҙжқҘдҝқеӯҳзҙўеј•гҖӮе®ғзҡ„ж•°жҚ®з»“жһ„иў«дјҳеҢ–д»ҘдҫҝеҸҜд»Ҙеҝ«йҖҹе’Ңжңүж•Ҳзҡ„еӯҳеҸ–ж•°жҚ®пјҲи§Ғ 4.2иҠӮ)гҖӮеҸҰеӨ–пјҢжҲ‘们и®ӨдёәпјҢзӣёеҜ№дәҺж–Үжң¬д»ҘеҸҠHTMLж–ҮжЎЈж•°йҮҸзҡ„еўһй•ҝпјҢзҙўеј•е’ҢеӯҳеӮЁиҠұиҙ№е®ғ们зҡ„иҙ№з”ЁжңҖз»ҲдјҡдёӢйҷҚ(и§Ғйҷ„еҪ•B)гҖӮеӣ жӯӨпјҢGoogleиҝҷж ·зҡ„йӣҶдёӯејҸпјҲиҜ‘иҖ…пјҡиҖҢйқһеҲҶеёғеҲ°и®ёеӨҡиҝңзЁӢи®Ўз®—жңәпјҢеҰӮP2Pзі»з»ҹпјүжҗңзҙўзі»з»ҹйҡҸзқҖдә’иҒ”зҪ‘зҡ„еҸ‘еұ•иҖҢжү©е®№е°ұжҲҗдёәеҸҜиғҪгҖӮ
1.3 и®ҫи®Ўзӣ®ж Ү
1.3.1 жҸҗй«ҳжҗңзҙўиҙЁйҮҸ
жҲ‘们зҡ„дё»иҰҒзӣ®ж ҮжҳҜжҸҗй«ҳwebжҗңзҙўеј•ж“Һзҡ„иҙЁйҮҸгҖӮеңЁ1994е№ҙпјҢдёҖдәӣдәәи®Өдёәз”ЁдёҖдёӘе®Ңж•ҙзҡ„жҗңзҙўзҙўеј•е°ұеҸҜд»ҘеҫҲе®№жҳ“ең°жүҫеҲ°д»»дҪ•дҝЎжҒҜгҖӮеңЁ1994е№ҙдә’иҒ”зҪ‘жңҖдҪіпјҚпјҚеҜјиҲӘе‘ҳдёҠпјҢжңүиҝҷж ·зҡ„иҜқ"жңҖеҘҪзҡ„еҜјиҲӘжңҚеҠЎеә”иҜҘжҳҜдҪҝз”ЁжҲ·еҸҜд»ҘеҫҲе®№жҳ“зҡ„еңЁWebдёҠжүҫеҲ°д»»дҪ•дҝЎжҒҜ"гҖӮ然иҖҢпјҢеҲ°1997пјҢиҝҷдёӘд»»еҠЎд»ҚжҳҜйқһеёёеӣ°йҡҫзҡ„гҖӮеңЁжңҖиҝ‘дҪҝз”Ёжҗңзҙўеј•ж“Һзҡ„з”ЁжҲ·йғҪеҸҜд»ҘеҫҲе®№жҳ“зҡ„иҜҒе®һзҙўеј•зҡ„е®Ңж•ҙжҖ§е№¶дёҚжҳҜеҶіе®ҡжҗңзҙўз»“жһңиҙЁйҮҸзҡ„е”ҜдёҖеӣ зҙ гҖӮ"еһғеңҫз»“жһң" з»ҸеёёдјҡдҪҝз”ЁжҲ·жүҫдёҚеҲ°зңҹжӯЈж„ҹе…ҙи¶Јзҡ„з»“жһңгҖӮе®һйҷ…дёҠпјҢеҲ°1997е№ҙзҡ„еҚҒдёҖжңҲпјҢеӣӣдёӘйЎ¶зә§жҗңзҙўеј•ж“ҺдёӯпјҢд»…д»…еҸӘжңүдёҖдёӘеҸҜд»ҘеңЁжҗңзҙўж—¶еҸ‘зҺ°е®ғиҮӘиә«(еҜ№жҹҘиҜўиҮӘе·ұеҗҚеӯ—зҡ„иҜ·жұӮпјҢиҝ”еӣһз»“жһңдёӯе°ҶиҮӘе·ұжҺ’еңЁз»“жһңдёӯзҡ„еүҚеҚҒеҗҚ)гҖӮдә§з”ҹиҝҷдёӘй—®йўҳзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖжҳҜеңЁиҝҷдәӣжҗңзҙўеј•ж“Һзҡ„зҙўеј•еә“дёӯж–ҮжЎЈзҡ„ж•°йҮҸжҲҗж•°йҮҸзә§ең°еўһй•ҝпјҢиҖҢз”ЁжҲ·зңӢиҝҷд№ҲеӨҡж–ҮжЎЈзҡ„иғҪеҠӣеҚҙдёҚеҸҜиғҪиҝҷж ·еўһй•ҝгҖӮз”ЁжҲ·еҫҖеҫҖеҸӘзңӢз»“жһңдёӯзҡ„еүҚж•°еҚҒдёӘгҖӮеӣ жӯӨпјҢйҡҸзқҖж–Ү档规模зҡ„еўһеҠ пјҢжҲ‘们йңҖиҰҒе·Ҙе…·жқҘжҸҗй«ҳжҹҘеҮҶзҺҮпјҲеңЁеүҚеҚҒдёӘз»“жһңдёӯиҝ”еӣһзӣёе…іеҶ…е®№пјүгҖӮе®һйҷ…дёҠпјҢжҲ‘们иҜҙзҡ„"зӣёе…і"жҳҜжҢҮжңҖеҘҪзҡ„йӮЈдёҖд»ҪпјҢеӣ дёәеҸҜиғҪдјҡжңүеҮ дёҮд»ҪвҖңзЁҚеҫ®вҖңзӣёе…ізҡ„ж–ҮжЎЈгҖӮжҹҘеҮҶзҺҮеңЁжҲ‘们зҡ„зңјдёӯжҳҜеҰӮжӯӨзҡ„йҮҚиҰҒпјҢд»ҘиҮідәҺжҲ‘们з”ҡиҮіж„ҝж„ҸдёәжӯӨжҚҹеӨұдёҖдәӣжҹҘе…ЁзҺҮгҖӮжңҖиҝ‘зҡ„з ”з©¶жҳҫзӨәпјҢи¶…ж–Үжң¬ж–Ү件дёӯзҡ„дҝЎжҒҜеҸҜд»ҘжңүеҠ©дәҺжҸҗй«ҳжҗңзҙўе’Ңе…¶д»–еә”з”Ё[Marchiori 97] [Spertus 97] [Weiss 96] [Kleinberg 98]гҖӮзү№еҲ«жҳҜзҪ‘йЎөй“ҫжҺҘзҡ„з»“жһ„пјҢд»ҘеҸҠй“ҫжҺҘжң¬иә«зҡ„ж–Үеӯ—пјҢдёәзӣёе…іжҖ§еҲӨе®ҡе’ҢиҝӣиЎҢиҙЁйҮҸзҡ„зӯӣйҖүжҸҗдҫӣдәҶи®ёеӨҡдҝЎжҒҜгҖӮGoogleдҪҝз”ЁдәҶзҪ‘йЎөй“ҫжҺҘз»“жһ„е’Ңй”ҡпјҲиҜ‘иҖ…пјҡHTMLдёӯзҡ„иҜӯжі•пјҢиЎЁзӨәдёҖдёӘжҢҮеҗ‘зҪ‘йЎөзҡ„й“ҫжҺҘпјүй“ҫжҺҘдёӯзҡ„ж–Үеӯ—гҖӮпјҲиҜҰи§Ғ2.1е’Ң2.2иҠӮпјү
1.3.2 жҗңзҙўеј•ж“Һзҡ„зҗҶи®әз ”з©¶
йҡҸзқҖWEBзҡ„е·ЁеӨ§еҸ‘еұ•пјҢдә’иҒ”зҪ‘д№ҹи¶ҠжқҘи¶Ҡе•ҶдёҡеҢ–гҖӮеңЁ1993е№ҙпјҢеҸӘжңү1.5%зҡ„webжңҚеҠЎеҷЁжҳҜ.comзҡ„еҹҹеҗҚгҖӮиҖҢеҲ°дәҶ1997е№ҙпјҢиҝҷдёӘж•°еӯ—е·Із»ҸеҸҳжҲҗдәҶ60%гҖӮеҗҢж—¶пјҢжҗңзҙўеј•ж“Һзҡ„д»ҺеӯҰжңҜз ”з©¶еҸҳжҲҗдәҶе•ҶдёҡжҖ§иҙЁгҖӮеҲ°зӣ®еүҚдёәжӯўпјҢеӨ§еӨҡж•°зҡ„жҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘йғҪжҳҜз”ұе…¬еҸёжқҘиҝӣиЎҢзҡ„пјҢеҫҲе°‘жңүиҜҰз»Ҷзҡ„жҠҖжңҜиө„ж–ҷиў«е…¬ејҖгҖӮиҝҷеҜјиҮҙдәҶиҝҷйЎ№жҠҖжңҜеёҰжңүдәҶи®ёеӨҡзҘһз§ҳзҡ„иүІеҪ©пјҢ并且жҳҜд»Ҙе№ҝе‘Ҡдёәдё»пјҲи§Ғйҷ„еҪ•AпјүгҖӮеҜ№дәҺGoogleпјҢжҲ‘们жңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„зӣ®ж Үе°ұжҳҜжҺЁеҠЁжҗңзҙўеј•ж“ҺеңЁеӯҰжңҜз•Ңзҡ„еҸ‘еұ•е’ҢзҗҶи§ЈгҖӮ
еҸҰеӨ–зҡ„йҮҚиҰҒзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜе»әз«ӢдёҖдёӘеҸҜд»Ҙи®©дёҖе®ҡж•°йҮҸзҡ„з”ЁжҲ·е®һйҷ…дҪҝз”Ёзҡ„зі»з»ҹгҖӮз”ЁжҲ·дҪҝз”ЁеҜ№жҲ‘们жқҘиҜҙйқһеёёйҮҚиҰҒпјҢеӣ дёәжҲ‘们и®ӨдёәзңҹжӯЈеҲ©з”ЁдәҶзҺ°д»Јдә’иҒ”зҪ‘зі»з»ҹзҡ„жө·йҮҸж•°жҚ®зҡ„з ”з©¶жүҚжҳҜжңҖжңүд»·еҖјзҡ„гҖӮжҜ”еҰӮзҺ°еңЁжҜҸеӨ©жңүж•°еҚғдёҮз”ЁжҲ·жҹҘиҜўпјҢдҪҶз”ұдәҺиҝҷдәӣж•°жҚ®иў«и®Өдёәе…·жңүе•Ҷдёҡд»·еҖјпјҢеҫҲйҡҫжӢҝжқҘдҪңеӯҰжңҜз ”з©¶гҖӮ
жҲ‘们жңҖз»Ҳзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜе»әз«ӢдёҖдёӘеҸҜд»Ҙж”ҜжҢҒеңЁеӨ§и§„жЁЎдә’иҒ”зҪ‘ж•°жҚ®дёҠиҝӣиЎҢз ”з©¶жҙ»еҠЁзҡ„зі»з»ҹжһ„жһ¶гҖӮдёәдәҶж”ҜжҢҒз ”з©¶жҙ»еҠЁпјҢGoogleеӯҳеӮЁдәҶе…ЁйғЁзҡ„еңЁзҲ¬иЎҢжҗңзҙўдёӯеҸ‘зҺ°зҡ„е®һйҷ…ж•°жҚ®пјҢ并еҺӢзј©иө·жқҘгҖӮдё»иҰҒзҡ„зӣ®ж Үд№ӢдёҖжҳҜе»әз«ӢдёҖдёӘзҺҜеўғпјҢеңЁиҝҷдёӘзҺҜеўғдёӯпјҢз ”з©¶иҖ…еҸҜд»ҘеҫҲеҝ«зҡ„еҲ©з”ЁиҝҷдёӘйҡҫеҫ—зҡ„зі»з»ҹпјҢеӨ„зҗҶwebж•°жҚ®пјҢдә§з”ҹд»Өдәәж„ҹе…ҙи¶Јзҡ„з»“жһңгҖӮеңЁзҹӯж—¶й—ҙеҶ…зі»з»ҹе°ұиў«е»әз«Ӣиө·жқҘпјҢе·Із»ҸжңүдёҖдәӣи®әж–ҮдҪҝз”ЁдәҶйҖҡиҝҮGoogleз”ҹжҲҗзҡ„ж•°жҚ®еә“гҖӮиҝҳжңүи®ёеӨҡе…¶е®ғзҡ„йЎ№зӣ®еңЁиҝӣиЎҢд№ӢдёӯгҖӮеҸҰеӨ–зҡ„зӣ®ж ҮжҳҜжҲ‘们еёҢжңӣе»әз«ӢдёҖдёӘзұ»дјјз©әй—ҙз«ҷзҡ„зҺҜеўғпјҢдҪҝеҫ—з ”з©¶иҖ…пјҢз”ҡиҮіжҳҜеӯҰз”ҹеҸҜд»ҘеңЁжҲ‘们зҡ„еӨ§и§„жЁЎwebж•°жҚ®дёҠиҝӣиЎҢе®һйӘҢгҖӮ
гҖ”жіЁ 1гҖ•зҲ¬иЎҢжҗңзҙўпјҢCrawlпјҢжҳҜжҢҮжҗңзҙўеј•ж“Һдјҡи·ҹйҡҸзҪ‘йЎөй—ҙзҡ„й“ҫжҺҘд»ҺдёҖдёӘзҪ‘йЎөвҖңзҲ¬иЎҢвҖқеҲ°дёӢдёҖдёӘзҪ‘йЎөгҖӮиҖҢеҜ№жҜҸдёҖдёӘзҪ‘йЎөзҡ„еҲҶжһҗе’Ңи®°еҪ•пјҢжҲ–иҖ…иҝҷдёӘиҝҮзЁӢзҡ„з»“жһңпјҢеҲҷз§°дёәвҖңзҙўеј•вҖқгҖӮ
2.зі»з»ҹеҠҹиғҪ
Googleжҗңзҙўеј•ж“ҺйҖҡиҝҮдёӨдёӘйҮҚиҰҒеҠҹиғҪжқҘдә§з”ҹй«ҳзІҫзЎ®еәҰзҡ„з»“жһңгҖӮ第дёҖпјҢе®ғеҲ©з”Ёдә’иҒ”зҪ‘зҡ„й“ҫжҺҘз»“жһ„дёәжҜҸдёӘзҪ‘йЎөи®Ўз®—еҮәдёҖдёӘй«ҳиҙЁйҮҸзҡ„жҺ’еҗҚгҖӮиҝҷдёӘжҺ’еҗҚиў«з§°дёәPageRank[жіЁдёҖ]пјҢе…·дҪ“еңЁLarry Page98е№ҙзҡ„и®әж–Ү[Page 98]дёӯжңүиҜҰиҝ°гҖӮ第дәҢпјҢGoogleеҲ©з”Ёй“ҫжҺҘжң¬иә«жқҘжҸҗй«ҳжҗңзҙўз»“жһңзҡ„иҙЁйҮҸгҖӮ
2.1 PageRank: з»ҷдә’иҒ”зҪ‘еёҰжқҘ秩еәҸ
зҺ°жңүзҡ„жҗңзҙўеј•ж“ҺеңЁеҫҲеӨ§зЁӢеәҰдёҠеҝҪз•ҘдәҶдёҖдёӘйҮҚиҰҒиө„жәҗпјҚпјҚжҠҠдә’иҒ”зҪ‘зңӢеҒҡжҳҜдёҖдёӘеј•з”Ёе…ізі»пјҲй“ҫжҺҘе…ізі»пјүеӣҫпјҲи§Ғ第дёҖйғЁеҲҶзҡ„жіЁи§ЈпјүгҖӮжҲ‘们已з»Ҹдә§з”ҹдәҶеҢ…еҗ«5дәҝ1еҚғ8зҷҫдёҮиҝҷж ·зҡ„и¶…ж–Үжң¬й“ҫжҺҘпјҲе°ұжҳҜзҪ‘йЎөжҢҮеҗ‘зҪ‘йЎөзҡ„й“ҫжҺҘпјүзҡ„ең°еӣҫпјҚпјҚиҝҷжҳҜеҜ№ж•ҙдёӘдә’иҒ”зҪ‘зҡ„дёҖдёӘзӣёеҪ“жҳҫи‘—зҡ„йҮҮж ·гҖӮиҝҷж ·зҡ„ең°еӣҫи®©жҲ‘们иғҪеҝ«йҖҹи®Ўз®—зҪ‘йЎөзҡ„вҖңPageRankвҖқпјҚпјҚдёҖдёӘеҜ№дәҺзҪ‘йЎөиў«еј•з”ЁзЁӢеәҰзҡ„е®ўи§ӮиЎЎйҮҸпјҢиҖҢиў«еј•з”ЁзЁӢеәҰдёҺдәә们еҜ№дәҺзҪ‘йЎөйҮҚиҰҒжҖ§зҡ„дё»и§Ӯи®ӨиҜҶд№ҹеҫҲеҘҪең°еҗ»еҗҲгҖӮз”ұдәҺиҝҷж ·зҡ„еҗ»еҗҲпјҢPageRankжҲҗдёәеҜ№з”Ёе…ій”®еӯ—жҗңзҙўзҪ‘йЎөиҝ”еӣһзҡ„з»“жһңиҝӣиЎҢжҺ’еәҸзҡ„жһҒеҘҪж–№ејҸгҖӮеҜ№дәҺжңҖзғӯй—Ёзҡ„еҲҶзұ»пјҢеұҖйҷҗдәҺзҪ‘йЎөж ҮйўҳиҝӣиЎҢз®ҖеҚ•зҡ„ж–Үеӯ—жҹҘжүҫпјҢPageRankжҺ’еәҸеҗҺзҡ„жҗңзҙўз»“жһңж•ҲжһңжһҒеҘҪгҖӮиҖҢеңЁж•ҙдёӘGoogleзі»з»ҹдёӯиҝӣиЎҢе…Ёж–ҮжҹҘжүҫпјҢPageRankзҡ„дҪңз”Ёд№ҹжҳҜйқһеёёжҳҫи‘—зҡ„гҖӮ
2.1.1 PageRank и®Ўз®—з®Җиҝ°
еӯҰжңҜж–ҮзҢ®зҡ„еј•з”ЁжңәеҲ¶иў«еә”з”ЁеҲ°дә’иҒ”зҪ‘дёҠпјҚпјҚдё»иҰҒе°ұжҳҜи®Ўз®—дёҖдёӘзҪ‘йЎөиў«еј•з”ЁпјҢжҲ–иў«еҸҚеҗ‘й“ҫжҺҘзҡ„ж¬Ўж•°гҖӮиҝҷз»ҷеҮәдәҶеҜ№дёҖдёӘзҪ‘йЎөйҮҚиҰҒжҖ§жҲ–иҙЁйҮҸзҡ„дј°и®ЎгҖӮPageRankиҝӣдёҖжӯҘеҸ‘еұ•дәҶиҝҷдёӘжғіжі•пјҡжқҘиҮӘдёҚеҗҢйЎөйқўзҡ„й“ҫжҺҘиў«з»ҷд»ҘдёҚеҗҢзҡ„жқғйҮҚпјҢ并дҫқжҚ®дёҖдёӘзҪ‘йЎөдёҠй“ҫжҺҘзҡ„дёӘж•°жӯЈжҖҒеҢ–гҖӮPageRankзҡ„е®ҡд№үеҰӮдёӢпјҡ
жҲ‘们еҒҮе®ҡзҪ‘йЎөгҖҖAгҖҖжңүиӢҘе№Іе…¶д»–зҪ‘йЎөпјҲT1...TnпјүжҢҮеҗ‘е®ғпјҲеҚіеј•з”Ёе…ізі»пјүгҖӮеҸӮж•°dжҳҜдёҖдёӘ0,1д№Ӣй—ҙзҡ„йҳ»е°јзі»ж•°гҖӮжҲ‘们йҖҡеёёжҠҠdи®ҫдёә0.85гҖӮдёӢдёҖиҠӮдјҡжңүе…ідәҺdзҡ„иҜҰиҝ°гҖӮC(A)жҳҜд»ҺзҪ‘йЎөAжҢҮеҗ‘е…¶д»–зҪ‘йЎөзҡ„й“ҫжҺҘдёӘж•°гҖӮйӮЈд№ҲзҪ‘йЎөAзҡ„PageRankзҡ„и®Ўз®—еҰӮдёӢпјҡ
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
жҲ‘们注ж„ҸеҲ°PageRankжһ„жҲҗдёҖдёӘеҲҶеёғдәҺжүҖжңүзҪ‘йЎөдёҠзҡ„жҰӮзҺҮеҲҶеёғеҮҪж•°пјҢеӣ жӯӨжүҖжңүзҪ‘йЎөзҡ„PageRankжҖ»е’Ңеә”иҜҘдёәгҖҖ1гҖӮ
PageRankпјҢжҲ–PR(A)еҸҜд»ҘйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„еҫӘзҺҜз®—жі•жқҘи®Ўз®—гҖӮиҝҷеҜ№еә”дәҺжӯЈжҖҒеҢ–еҗҺзҡ„дә’иҒ”зҪ‘й“ҫжҺҘзҹ©йҳөзҡ„дё»иҰҒиүҫж №еҗ‘йҮҸзҡ„и®Ўз®—гҖӮеҸҰеӨ–пјҢ2еҚғ6зҷҫдёҮзҪ‘йЎөзҡ„PageRankеҸҜд»ҘеңЁдёҖеҸ°дёӯеһӢжңҚеҠЎеҷЁдёҠпјҢйҖҡиҝҮеҮ е°Ҹж—¶зҡ„и®Ўз®—е®ҢжҲҗгҖӮиҝҷйҮҢжңүеҫҲеӨҡз»ҶиҠӮи¶…еҮәдәҶжң¬и®әж–Үзҡ„и®Ёи®әиҢғеӣҙгҖӮ
2.1.2 зӣҙи§Ӯи§ЈйҮҠ
PageRank еҸҜд»Ҙиў«жғіеғҸжҲҗдёҖдёӘеҜ№з”ЁжҲ·иЎҢдёәе»әз«Ӣзҡ„жЁЎеһӢгҖӮжҲ‘们еҒҮжғідёҖдёӘвҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқпјӣйҡҸжңәең°з»ҷд»–дёҖдёӘзҪ‘йЎөпјӣд»–жј«ж— зӣ®зҡ„ең°зӮ№еҮ»зҪ‘йЎөзҡ„й“ҫжҺҘпјҢиҖҢд»ҺжқҘдёҚзӮ№вҖңиҝ”еӣһй”®вҖқпјӣжңҖз»Ҳд»–и§үеҫ—зғҰдәҶпјҢеҸҲд»ҺеҸҰдёҖдёӘйҡҸжңәзҡ„зҪ‘йЎөд»Һж–°ејҖе§ӢгҖӮеңЁдёҠиҝ°жЁЎеһӢдёӯпјҢвҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқи®ҝй—®дёҖдёӘйЎөйқўзҡ„жҰӮзҺҮе°ұжҳҜиҝҷдёӘйЎөйқўзҡ„PageRankгҖӮиҖҢйҳ»е°јзі»ж•°dпјҢеҲҷжҳҜжҲ‘们зҡ„вҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқеңЁи®ҝй—®дәҶдёҖдёӘйЎөйқўеҗҺпјҢи§үеҫ—зғҰдәҶпјҢејҖе§Ӣи®ҝй—®дёҖдёӘж–°зҡ„йЎөйқўзҡ„жҰӮзҺҮгҖӮдёҠиҝ°жЁЎеһӢзҡ„дёҖдёӘйҮҚиҰҒеҸҳеҪўжҳҜжҠҠйҳ»е°јзі»ж•°dеҠ еҲ°дёҖдёӘзҪ‘йЎөдёҠпјҢиҝҳжҳҜеҠ еҲ°дёҖз»„зҪ‘йЎөдёҠгҖӮиҝҷдёӘеҸҳеҪўдҪҝеҫ—ж•…ж„Ҹж¬әйӘ—зі»з»ҹиҺ·еҫ—й«ҳжҺ’еҗҚзҡ„дјҒеӣҫеҮ д№ҺеҸҳжҲҗдёҚеҸҜиғҪзҡ„гҖӮжҲ‘们еҜ№PageRankжңүиӢҘ干延伸пјҢиҜҰи§ҒиҝҷйҮҢ[Page 98]гҖӮ
еҸҰдёҖдёӘзӣҙи§Ӯзҡ„и§ЈйҮҠжҳҜеҰӮжһңжңүеҫҲеӨҡе…¶д»–зҪ‘йЎөжҢҮеҗ‘дёҖдёӘйЎөйқўпјҢжҲ–иҖ…е…¶д»–жңүеҫҲй«ҳPageRankзҡ„зҪ‘йЎөжҢҮеҗ‘иҝҷдёӘйЎөйқўпјҢиҜҘйЎөйқўеә”иҜҘжңүиҫғй«ҳзҡ„PageRankгҖӮзӣҙи§үе‘ҠиҜүжҲ‘们пјҢеҰӮжһңдёҖдёӘзҪ‘йЎөиў«дә’иҒ”зҪ‘дёҠзҡ„еҫҲеӨҡе…¶д»–зҪ‘йЎөеј•з”ЁпјҢе®ғеә”иҜҘжҳҜеҖјеҫ—е…іжіЁзҡ„гҖӮиҖҢйӮЈдәӣеҸӘжңүдёҖдёӘеј•з”Ёзҡ„йЎөйқўпјҢеҰӮжһңе®ғжқҘиҮӘиұЎYahoo!йҰ–йЎөпјҢйӮЈеӨ§зәҰиҝҷдёӘзҪ‘йЎөд№ҹеҖјеҫ—зңӢзңӢгҖӮеҰӮжһңдёҖдёӘзҪ‘йЎөиҙЁйҮҸдёҚй«ҳжҲ–ж №жң¬е°ұжҳҜдёҖдёӘжӯ»й“ҫжҺҘпјҢYahooйҰ–йЎөеӨҡеҚҠдёҚдјҡй“ҫжҺҘе®ғгҖӮPageRankгҖҖиҖғиҷ‘дәҶдёҠиҝ°дёӨз§Қд»ҘеҸҠд№Ӣй—ҙзҡ„еҗ„з§Қжғ…еҶөпјҢе®ғз”ЁйҖ’еҪ’ж–№ејҸжҠҠзҪ‘йЎөзҡ„жқғйҮҚйҖҡиҝҮдә’иҒ”зҪ‘зҡ„й“ҫжҺҘз»“жһ„дј ж’ӯеҮәеҺ»гҖӮ
2.2 й”ҡй“ҫжҺҘпјҲAnchorпјҢжҳҜHTMLзҡ„иҜӯжі•пјҢеҚізҪ‘йЎөй“ҫжҺҘпјүзҡ„ж–Үжң¬
й“ҫжҺҘзҡ„ж–Үеӯ—еңЁжҲ‘们зҡ„жҗңзҙўеј•ж“ҺдёӯеҸ—еҲ°зү№ж®ҠеӨ„зҗҶгҖӮеӨ§еӨҡж•°жҗңзҙўеј•ж“ҺжҠҠй“ҫжҺҘдёӯзҡ„ж–Үжң¬йғЁеҲҶпјҲжҜ”еҰӮkesoиҝҷдёӘй“ҫжҺҘдёӯзҡ„kesoпјүеҪ’еұһдәҺиҝҷдёӘй“ҫжҺҘжүҖеңЁзҡ„зҪ‘йЎөгҖӮиҖҢжҲ‘们йҷӨжӯӨд№ӢеӨ–пјҢиҝҳжҠҠе®ғеҪ’еұһдәҺиҝҷдёӘй“ҫжҺҘжҢҮеҗ‘зҡ„йЎөйқўгҖӮиҝҷжңүеҮ дёӘеҘҪеӨ„гҖӮ第дёҖпјҢй”ҡй“ҫжҺҘеҜ№иў«жҢҮеҗ‘зҪ‘йЎөзҡ„жҸҸиҝ°пјҢйҖҡеёёжҜ”зҪ‘йЎөжң¬иә«зҡ„жҸҸиҝ°жӣҙеҮҶзЎ®гҖӮ第дәҢпјҢй”ҡй“ҫжҺҘеҸҜиғҪжҢҮеҗ‘йӮЈдәӣдёҚиғҪиў«е»әз«Ӣж–Үжң¬зҙўеј•зҡ„ж–ҮжЎЈпјҢеҰӮеӣҫзүҮгҖҒзЁӢеәҸгҖҒж•°жҚ®еә“гҖӮиҝҷдҪҝеҫ—зҺ°еңЁдёҚиғҪзҲ¬иЎҢжҗңзҙўзҡ„йЎөйқўеҸҜд»Ҙиў«жҗңзҙўеҲ°дәҶгҖӮжіЁж„ҸпјҢд»ҘеүҚд»ҺжңӘиў«зҲ¬иЎҢжҗңзҙўиҝҮзҡ„йЎөйқўеҸҜиғҪдјҡдә§з”ҹй—®йўҳпјҢеӣ дёәе®ғ们зҡ„жңүж•ҲжҖ§д»ҺжңӘиў«йӘҢиҜҒиҝҮгҖӮжҜ”еҰӮжҗңзҙўеј•ж“Һз”ҡиҮідјҡиҝ”еӣһдёҖдёӘжңүй“ҫжҺҘжҢҮеҗ‘пјҢдҪҶе…¶е®һж №жң¬дёҚеӯҳеңЁзҡ„йЎөйқўгҖӮ然иҖҢпјҢз”ұдәҺжҲ‘们еҸҜд»ҘеҜ№з»“жһңжҺ’еәҸпјҢиҝҷдёӘй—®йўҳеҫҲе°‘дјҡеҮәзҺ°гҖӮ
жҠҠй”ҡй“ҫжҺҘдёӯзҡ„ж–Үжң¬дј ж’ӯеҲ°иў«жҢҮеҗ‘зҡ„йЎөйқўиҝҷдёӘжғіжі•пјҢеңЁWorld Wide Web Worm [McBryan 94] е·Із»Ҹиў«е®һж–ҪдәҶгҖӮдё»иҰҒз”ЁдәҺеҜ№йқһж–Үжң¬ж–Ү件зҡ„жҗңзҙўпјҢе’ҢжҠҠжҗңзҙўз»“жһңжү©еұ•еҲ°жӣҙеӨҡдёӢиҪҪж–ҮжЎЈгҖӮиҖҢжҲ‘们дҪҝз”Ёй”ҡй“ҫжҺҘпјҢдё»иҰҒжҳҜеӣ дёәе®ғеҸҜд»ҘжҸҗдҫӣй«ҳиҙЁйҮҸзҡ„з»“жһңгҖӮжңүж•ҲдҪҝз”Ёй”ҡй“ҫжҺҘеңЁжҠҖжңҜдёҠжҳҜеҫҲйҡҫе®һзҺ°зҡ„пјҢеӣ дёәеӨ§йҮҸж•°жҚ®йңҖиҰҒеӨ„зҗҶгҖӮеңЁжҲ‘们зҺ°еңЁзҲ¬иЎҢжҗңзҙўиҝҮзҡ„2еҚғ4зҷҫдёҮзҪ‘йЎөдёӯпјҢжҲ‘们дёә2дәҝ5еҚғ9зҷҫдёҮй”ҡй“ҫжҺҘе»әз«ӢдәҶзҙўеј•гҖӮ
2.3 е…¶д»–еҠҹиғҪ
йҷӨдәҶдҪҝз”ЁPageRankе’ҢеҲ©з”Ёй”ҡй“ҫжҺҘдёӯзҡ„ж–Үжң¬еӨ–пјҢGoogleиҝҳжңүе…¶д»–дёҖдәӣеҠҹиғҪгҖӮ第дёҖпјҢе®ғжңүжүҖжңүзҪ‘йЎөзҡ„дҪҚзҪ®дҝЎжҒҜпјҢеӣ жӯӨеңЁжҗңзҙўиҝҮзЁӢдёӯе……еҲҶеә”з”ЁдәҶжҺҘиҝ‘зЁӢеәҰгҖӮ第дәҢпјҢGoogleгҖҖи®°еҪ•зҪ‘йЎөзҡ„дёҖдәӣи§Ҷи§үиЎЁзҺ°пјҢеҰӮеҚ•иҜҚзҡ„еӯ—дҪ“еӨ§е°ҸгҖӮеӨ§еӯ—дҪ“зҡ„жқғйҮҚжҜ”е°Ҹеӯ—дҪ“иҰҒй«ҳгҖӮ第дёүпјҢе®Ңж•ҙзҡ„еҺҹе§ӢHTMLйЎөйқўиў«дҝқеӯҳдёӢжқҘпјҲеҚіGoogleзҡ„зҪ‘йЎөеҝ«з…§еҠҹиғҪпјүгҖӮ
[жіЁдёҖ]гҖҖPageRankгҖҖеҸҜд»ҘиҜ‘дёәзҪ‘йЎөжҺ’еҗҚпјҢе»әи®®еҗҺйқўе°ұз”ЁеҺҹж–ҮдәҶгҖӮеҸҰеӨ–пјҢPageгҖҖжҒ°жҒ°жҳҜGoogleеҲӣе§Ӣдәәд№ӢдёҖLarry Pageзҡ„姓гҖӮ
3зӣёе…іе·ҘдҪң
еҹәдәҺwebзҡ„жҗңзҙўз ”究жңүдёҖж®өз®Җзҹӯзҡ„зҡ„еҺҶеҸІгҖӮдёҮз»ҙзҪ‘и •иҷ«( wwww )[ mcbryan 94 ]жҳҜ第дёҖдёӘзҪ‘дёҠжҗңзҙўеј•ж“ҺгҖӮдҪҶйҡҸеҗҺ,дә§з”ҹдәҶеҮ дёӘеӯҰйҷўжҙҫзҡ„жҗңзҙўеј•ж“Һ,е…¶дёӯжңүдёҚе°‘зҺ°еңЁе·Із»ҸжҳҜе…¬ејҖзҡ„дёҠеёӮе…¬еҸёдәҶгҖӮзӣёжҜ”Webзҡ„еўһй•ҝе’Ңжҗңзҙўеј•ж“Һзҡ„йҮҚиҰҒжҖ§,зҺ°еңЁеҮ д№ҺжІЎжңүе…ідәҺеҪ“еүҚжҗңзҙўеј•ж“Һжңүд»·еҖјзҡ„з ”з©¶жқҗж–ҷ [Pinkerton 94].гҖӮжҚ®иҝҲе…Ӣе°”.иҢӮдёҒ( lycosе…¬еҸёйҰ–еёӯ科еӯҰ家)[Mauldin] "еҗ„з§ҚжңҚеҠЎ(еҢ…жӢ¬lycos )зҙ§еҜҶзҡ„е®ҲеҚ«зқҖиҝҷдәӣж•°жҚ®еә“" гҖӮ
дёҚиҝҮ,еңЁжҗңзҙўеј•ж“Һзҡ„е…·дҪ“зҡ„зү№зӮ№дёҠе·ІиҝӣиЎҢдәҶзӣёеҪ“зҡ„е·ҘдҪңгҖӮеҜ№зҺ°жңүе•Ҷдёҡжҗңзҙўеј•ж“Һдә§з”ҹзҡ„жҗңзҙўз»“жһңзҡ„еҗҺеӨ„зҗҶе·Із»ҸеҸ–еҫ—дәҶеҚ“жңүжҲҗж•Ҳзҡ„жҲҗжһң,жҲ–жҳҜдә§з”ҹе°Ҹ规模зҡ„вҖңдёӘжҖ§еҢ–зҡ„вҖңжҗңзҙўеј•ж“ҺгҖӮжңҖз»Ҳ,жңүиҝҮдёҚе°‘й’ҲеҜ№дҝЎжҒҜжЈҖзҙўзі»з»ҹзҡ„з ”з©¶,е°Өе…¶жҳҜеҜ№еҸ—жҺ§еҲ¶зҡ„з»“жһңйӣҶзҡ„з ”з©¶гҖӮеңЁйҡҸеҗҺдёӨиҠӮдёӯ,жҲ‘们е°Ҷи®Ёи®әдёҖдәӣеҝ…йЎ»жү©еӨ§з ”究зҡ„йўҶеҹҹ,д»ҘдҫҝжӣҙеҘҪең°еңЁWebдёҠе·ҘдҪңгҖӮ
3.1дҝЎжҒҜжЈҖзҙў
дҝЎжҒҜжЈҖзҙўзі»з»ҹзҡ„з ”з©¶,е·Із»ҸжңүеҫҲеӨҡе№ҙдәҶ,并且жҲҗжһңжҳҫи‘—[Witten 94] гҖӮ 然иҖҢ,еӨ§еӨҡж•°дҝЎжҒҜжЈҖзҙўзі»з»ҹ зҡ„ з ”з©¶ й’ҲеҜ№зҡ„жҳҜ еҸ—жҺ§еҲ¶зҡ„еҗҢиҙЁйӣҶеҗҲ пјҢдҫӢеҰӮ,дё»йўҳзӣёе…ізҡ„科еӯҰи®әж–ҮжҲ–ж–°й—»ж•…дәӢгҖӮзҡ„зЎ®,дҝЎжҒҜжЈҖзҙўзҡ„дё»иҰҒзҡ„еҹәеҮҶ,ж–Үжң¬жЈҖзҙўдјҡи®®[TREC 96] ,з”ЁдәҶдёҖдёӘзӣёеҪ“е°Ҹзҡ„пјҢ并且еҸ—жҺ§еҲ¶зҡ„йӣҶеҗҲ дҪңдёәе…¶еҹәеҮҶгҖӮвҖңйқһеёёеӨ§зҡ„иҜӯж–ҷеә“вҖң; еҹәеҮҶеҸӘжңү20gb еӨ§е°ҸпјҢ зӣёиҫғдәҺжҲ‘们жҗңзҙўиҝҮзҡ„ 2еҚғ4зҷҫдёҮзҪ‘йЎөпјҢжңү147gb зҡ„ж•°жҚ®йҮҸ гҖӮеңЁTREC дёҠе·ҘдҪңеҫҲеҘҪзҡ„жҗңзҙўеј•ж“ҺпјҢжӢҝеҲ°WebдёҠжқҘеҫҖеҫҖж•ҲжһңдёҚдҪігҖӮдёҫдҫӢжқҘиҜҙ,ж ҮеҮҶеҗ‘йҮҸз©әй—ҙжЁЎеһӢиҜ•еӣҫиҝ”еӣһе’ҢжҗңзҙўжқЎд»¶жңҖдёәиҝ‘дјјзҡ„ж–Ү件,еҒҮе®ҡжҗңзҙўе’Ңж–Ү件йғҪжҳҜеҗ„иҮӘж–Үеӯ—е®ҡд№үзҡ„еҗ‘йҮҸгҖӮеҜ№Web иҖҢиЁҖ,иҝҷз§Қзӯ–з•ҘеҸӘдјҡиҝ”еӣһйқһеёёз®Җзҹӯзҡ„ж–Ү件пјҢеҢ…еҗ«жҹҘиҜўжң¬иә«е’ҢеҮ еҸҘиҜқгҖӮдёҫдҫӢжқҘиҜҙ,жҲ‘们已з»ҸзңӢеҲ°дәҶдёҖдёӘдё»иҰҒзҡ„жҗңзҙўеј•ж“Һиҝ”еӣһзҡ„дёҖдёӘйЎөйқўд»…д»…еҗ«жңүвҖңжҜ”е°”.е…Ӣжһ—йЎҝзңҹзіҹвҖң;е’Ңд»ҺвҖңжҜ”е°”.е…Ӣжһ—йЎҝвҖңжҗңзҙўжқҘзҡ„еӣҫзүҮгҖӮ жңүдәәдәүи®әеҲ° ,еңЁWebдёҠз”ЁжҲ·еә”иҜҘжӣҙе…·дҪ“,жӣҙеҮҶзЎ®ең°жҢҮеҮә他们иҰҒд»Җд№Ҳ,并且еңЁжҗңзҙўжҹҘиҜўдёӯеўһж·»жӣҙеӨҡиҜҚгҖӮжҲ‘们еқҡеҶіеҸҚеҜ№иҝҷз§Қз«ӢеңәгҖӮеҰӮжһңз”ЁжҲ·еҸ‘еҮәеҜ№вҖңжҜ”е°”е…Ӣжһ—йЎҝвҖңзҡ„жҗңзҙўжҹҘиҜў ,他们еә”еҫ—еҲ°еҗҲзҗҶзҡ„з»“жһң,еӣ дёәе°ұиҝҷдёӘиҜқйўҳеӯҳеңЁзқҖеӨ§йҮҸзҡ„й«ҳе“ҒиҙЁзҡ„иө„ж–ҷгҖӮйүҙдәҺиҝҷдёҖзұ»зҡ„дҫӢеӯҗ,жҲ‘们и®Өдёәж ҮеҮҶзҡ„дҝЎжҒҜжЈҖзҙўе·ҘдҪңйңҖиҰҒжү©еӨ§иҢғеӣҙпјҢд»ҺиҖҢжңүж•ҲеӨ„зҗҶ WebгҖӮ
3.2 Webе’ҢеҸ—жҺ§йӣҶеҗҲзҡ„дёҚеҗҢ
дә’иҒ”зҪ‘ WebжҳҜдёҖдёӘе№ҝйҳ”зҡ„е……ж»Ўе®Ңе…ЁдёҚеҸ—жҺ§еҲ¶зҡ„ејӮжһ„ж–Ү件зҡ„йӣҶеҗҲгҖӮWeb дёҠзҡ„ж–Ү件,дёҚдҪҶеҶ…йғЁж јејҸжһҒе…¶дёҚеҗҢ,иҖҢдё”еӨ–йғЁе…ғдҝЎжҒҜд№ҹжңӘеҝ…еҸҜз”ЁгҖӮдҫӢеҰӮ,ж–Ү件еҶ…йғЁзҡ„дёҚеҗҢ,жңүеҗ„иҮӘзҡ„иҜӯиЁҖ(еҢ…жӢ¬иҮӘ然иҜӯиЁҖе’Ңзј–зЁӢиҜӯиЁҖ),еҗ„иҮӘзҡ„иҜҚжұҮ(з”өеӯҗйӮ®д»¶ең°еқҖ,й“ҫжҺҘ,йӮ®зј–,з”өиҜқеҸ·з Ғ,дә§е“ҒеҸ·з Ғ)пјҢж–Үд»¶ж јејҸзҡ„дёҚеҗҢ(ж–Үжң¬ж јејҸ, htmlж јејҸ, pdfж јејҸ,еӣҫеғҸж јејҸ,еЈ°йҹіж јејҸ),并且з”ҡиҮіеҸҜиғҪжҳҜжңәеҷЁдә§з”ҹзҡ„(ж—Ҙеҝ—ж–Ү件жҲ–иҖ…ж•°жҚ®еә“зҡ„иҫ“еҮәж–Ү件) гҖӮеңЁеҸҰдёҖж–№йқў,жҲ‘们е®ҡд№үж–Ү件зҡ„еӨ–йғЁе…ғдҝЎжҒҜпјҢд»ҺиҝҷдәӣдҝЎжҒҜе°ұеҸҜд»ҘжҺЁж–ӯеҮәдёҖдёӘж–Ү件зҡ„еӨ§жҰӮ,дҪҶжҳҜе…ғдҝЎжҒҜ并дёҚеҢ…еҗ«еңЁж–Ү件дёӯгҖӮж–Ү件еӨ–йғЁе…ғдҝЎжҒҜзҡ„дҫӢеӯҗ,еҢ…жӢ¬иҝҷж ·дёҖдәӣдҝЎжҒҜпјҡ жқҘжәҗзҡ„еЈ°иӘү,жӣҙж–°йў‘зҺҮ,иҙЁйҮҸ,еҸ—ж¬ўиҝҺзЁӢеәҰ е’Ң з”Ёжі• , е’Ңеј•з”ЁгҖӮдёҚд»…жҳҜеӨ–йғЁе…ғдҝЎжҒҜзҡ„еҸҜиғҪжқҘжәҗеҚғе·®дёҮеҲ«,иҖҢдё”иЎЎйҮҸзҡ„ж–№ејҸд№ҹеӯҳеңЁеҫҲеӨҡдёҚеҗҢж•°йҮҸзә§зҡ„е·®ејӮгҖӮдёҫдҫӢжқҘиҜҙ,жҜ”иҫғд»ҺдёҖдёӘеӨ§еһӢзҪ‘з«ҷзҡ„дё»йЎөеҫ—еҲ°зҡ„дҪҝз”ЁдҝЎжҒҜ,еҰӮпјҢйӣ…иҷҺпјҢзӣ®еүҚжҜҸеӨ©иҺ·еҫ—еҮ зҷҫдёҮзҡ„йЎөйқўжөҸи§ҲйҮҸпјҢ иҖҢдёҖдёӘжҷҰ涩зҡ„еҺҶеҸІж–Үз« ,еҸҜиғҪжҜҸ10е№ҙжүҚиғҪиў«жөҸи§ҲдёҖж¬ЎгҖӮжҳҫиҖҢжҳ“и§Ғ,жҗңзҙўеј•ж“Һеҝ…йЎ»дёҘйҮҚеҢәеҲ«еҜ№еҫ…иҝҷдёӨдёӘжқЎзӣ®гҖӮ
еҸҰдёҖдёӘWeb е’ҢеҸ—жҺ§йӣҶеҗҲзҡ„иҫғеӨ§е·®ејӮжҳҜ,еҮ д№ҺжІЎжңүйҷҗеҲ¶жҺ§еҲ¶дәә们еңЁзҪ‘дёҠеҸҜд»Ҙж”ҫд»Җд№ҲгҖӮжҠҠиҝҷз§ҚзҒөжҙ»жҖ§зҡ„еҶ…е®№еҸ‘еёғе’Ңдә§з”ҹе·ЁеӨ§еҪұе“Қзҡ„жҗңзҙўеј•ж“Һз»“еҗҲиө·жқҘ пјҢеҺ»еҗёеј•и®ҝй—®жөҸи§ҲйҮҸгҖӮ 并且еҫҲеӨҡе…¬еҸёйҖҡиҝҮж•…ж„Ҹж“Қзәөжҗңзҙўеј•ж“ҺжқҘиөўеҲ©пјҢж—ҘзӣҠжҲҗдёәдёҖдёӘдёҘйҮҚй—®йўҳгҖӮиҝҷдёӘй—®йўҳеңЁдј з»ҹзҡ„е°Ғй—ӯзҡ„дҝЎжҒҜжЈҖзҙўзі»з»ҹдёӯдёҖзӣҙжІЎжңүеҸ‘зҺ° гҖӮеҸҰеӨ–,жңүи¶Јзҡ„жҳҜжҲ‘们注ж„ҸеҲ°webжҗңзҙўеј•ж“ҺдҪҝеҫ—жғійҖҡиҝҮе…ғж•°жҚ®ж“Қзәөжҗңзҙўеј•ж“Һзҡ„еҠӘеҠӣеҹәжң¬дёҠеӨұиҙҘдәҶ,еӣ дёәзҪ‘йЎөдёҠзҡ„д»»дҪ•ж–Үеӯ—еҰӮжһңдёҚжҳҜз”ЁжқҘе‘ҲзҺ°з»ҷз”ЁжҲ·зҡ„пјҢ е°ұжҳҜиў«ж»Ҙз”ЁжқҘж“Қзәөжҗңзҙўеј•ж“ҺгҖӮз”ҡиҮіжңүи®ёеӨҡе…¬еҸёдё“й—Ёж“Қзәөжҗңзҙўеј•ж“Һд»ҘиҫҫеҲ°иөўеҲ©зҡ„зӣ®зҡ„гҖӮ
пјҲж–ӯж–ӯз»ӯз»ӯең°жҠҠе®ғзҝ»е®ҢдәҶгҖӮ第4йғЁеҲҶжҳҜGoogleжҗңзҙўеј•ж“ҺжңҖж ёеҝғзҡ„дёҖеқ—пјҢжңүдёҖдәӣи®ҫи®Ўз»ҶиҠӮиҝҳдёҚжҳҜеҫҲжҮӮпјҢеёҢжңӣиғҪе’ҢеӨ§е®¶дёҖиө·жҺўи®ЁгҖӮзҝ»иҜ‘дёҚеҪ“д№ӢеӨ„иҝҳиҜ·еҗ„дҪҚжҢҮеҮәпјҢи°ўи°ўгҖӮпјү
4 зі»з»ҹеү–жһҗпјҲSystem Anatomyпјү
йҰ–е…ҲпјҢжҲ‘们еҜ№жһ¶жһ„еҒҡдёҖдёӘй«ҳеұӮзҡ„и®Ёи®әгҖӮжҺҘзқҖпјҢеҜ№йҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„жңүдёҖдёӘж·ұе…Ҙзҡ„жҸҸиҝ°гҖӮжңҖеҗҺпјҢжҲ‘们е°Ҷж·ұе…ҘеҲҶжһҗдё»иҰҒзҡ„еә”з”ЁзЁӢеәҸпјҡзҲ¬иҷ«пјҢзҙўеј•е’ҢжҗңзҙўгҖӮ
4.1 Googleжһ¶жһ„жҰӮиҝ°
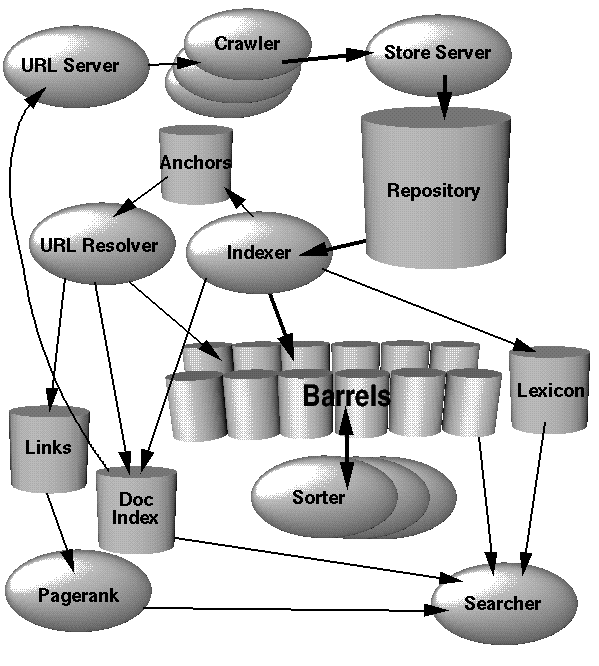
еӣҫ1. Googleй«ҳеұӮжһ¶жһ„
еңЁиҝҷдёҖйғЁеҲҶпјҢжҲ‘们е°ҶеҜ№еӣҫ1дёӯж•ҙдёӘзі»з»ҹжҳҜжҖҺд№ҲиҝҗиЎҢзҡ„жңүдёҖдёӘй«ҳеұӮзҡ„жҰӮиҝ°гҖӮиҝҷдёҖйғЁеҲҶжІЎжңүжҸҗеҲ°еә”з”ЁзЁӢеәҸе’Ңж•°жҚ®з»“жһ„пјҢиҝҷдәӣдјҡеңЁжҺҘдёӢжқҘзҡ„еҮ йғЁеҲҶйҮҢи®Ёи®әгҖӮиҖғиҷ‘еҲ°ж•ҲзҺҮпјҢGoogleзҡ„еӨ§йғЁеҲҶжҳҜз”ЁCжҲ–C++е®һзҺ°пјҢеҸҜд»ҘеңЁSolarisжҲ–иҖ…LinuxдёӢиҝҗиЎҢгҖӮ
еңЁGoogleдёӯпјҢзҪ‘йЎөжҠ“еҸ–пјҲдёӢиҪҪwebйЎөйқўпјүзҡ„е·ҘдҪңз”ұеҲҶеёғејҸзҡ„зҲ¬иҷ«пјҲcrawlersпјүе®ҢжҲҗгҖӮжңүдёҖдёӘURLжңҚеҠЎеҷЁпјҲеӣҫ1дёӯзҡ„URL ServerпјүжҠҠйңҖиҰҒжҠ“еҸ–зҡ„URLеҲ—иЎЁеҸ‘йҖҒз»ҷзҲ¬иҷ«гҖӮзҪ‘йЎөжҠ“еҸ–еҘҪд№ӢеҗҺиў«еҸ‘йҖҒеҲ°еӯҳеӮЁжңҚеҠЎеҷЁпјҲеӣҫ1дёӯзҡ„Store ServerпјүгҖӮжҺҘзқҖеӯҳеӮЁжңҚеҠЎеҷЁе°ҶжҠ“еҸ–жқҘзҡ„зҪ‘йЎөеҺӢ缩并еӯҳж”ҫеңЁд»“еә“(repository)йҮҢгҖӮжҜҸдёҖдёӘзҪ‘йЎөйғҪжңүдёҖдёӘдёҺд№Ӣзӣёе…ізҡ„IDпјҢеҸ«docIDгҖӮеңЁдёҖдёӘзҪ‘йЎөйҮҢжҜҸеҸ‘зҺ°дёҖдёӘж–°зҡ„URLпјҢе°ұдјҡиөӢдәҲе®ғдёҖдёӘIDгҖӮзҙўеј•еҠҹиғҪз”ұзҙўеј•еҷЁпјҲеӣҫ1дёӯзҡ„indexerпјүе’ҢжҺ’еәҸеҷЁпјҲеӣҫ1дёӯзҡ„sorterпјүе®ҢжҲҗгҖӮзҙўеј•еҷЁжңүеҫҲеӨҡеҠҹиғҪгҖӮе®ғд»Һд»“еә“дёӯиҜ»еҸ–пјҢи§ЈеҺӢ并еҲҶжһҗж–ҮжЎЈгҖӮжҜҸдёӘж–ҮжЎЈйғҪиў«иҪ¬еҢ–жҲҗдёҖдёӘиҜҚзҡ„йӣҶеҗҲпјҢиҜҚеҮәзҺ°дёҖж¬ЎеҸ«еҒҡдёҖдёӘе‘ҪдёӯпјҲhitsпјүгҖӮжҜҸжқЎе‘Ҫдёӯи®°еҪ•дәҶдёҖдёӘиҜҚпјҢиҝҷдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„дҪҚзҪ®пјҢеӯ—дҪ“еӨ§е°Ҹзҡ„иҝ‘дјјеҖјд»ҘеҸҠеӨ§е°ҸеҶҷдҝЎжҒҜгҖӮзҙўеј•еҷЁе°Ҷиҝҷдәӣе‘ҪдёӯеҲҶеёғеҲ°дёҖзі»еҲ—вҖңжЎ¶вҖқпјҲbarrelsпјүйҮҢйқўпјҢе»әз«ӢдёҖдёӘеҚҠжҺ’еәҸ(partially sorted)зҡ„жӯЈжҺ’зҙўеј•(forward index)гҖӮзҙўеј•еҷЁиҝҳжңүдёҖдёӘйҮҚиҰҒзҡ„еҠҹиғҪгҖӮе®ғи§ЈжһҗеҮәжҜҸеј зҪ‘йЎөйҮҢйқўзҡ„жүҖжңүй“ҫжҺҘпјҢ并жҠҠиҝҷдәӣй“ҫжҺҘзҡ„зӣёе…ійҮҚиҰҒдҝЎжҒҜеӯҳж”ҫеңЁдёҖдёӘй”ҡ(anchors)ж–Ү件йҮҢгҖӮиҝҷдёӘж–Ү件еҢ…еҗ«дәҶи¶іеӨҹзҡ„дҝЎжҒҜпјҢд»ҘжҳҫзӨәжҜҸдёӘй“ҫжҺҘд»Һе“ӘйҮҢиҝһжҺҘиҝҮжқҘпјҢй“ҫеҲ°е“ӘйҮҢе’Ңй“ҫжҺҘзҡ„жҸҸиҝ°гҖӮ
URLеҲҶи§ЈеҷЁпјҲURLresolverпјүиҜ»еҸ–й”ҡж–Ү件пјҢе°ҶзӣёеҜ№URLиҪ¬еҢ–дёәз»қеҜ№URLпјҢеҶҚиҪ¬еҢ–жҲҗdocIDгҖӮе®ғдёәй”ҡж–Үжң¬е»әз«ӢдёҖдёӘжӯЈжҺ’зҙўеј•пјҢ并дёҺй”ҡжҢҮеҗ‘зҡ„docIDе…іиҒ”иө·жқҘгҖӮе®ғиҝҳдә§з”ҹдёҖдёӘжңүdocIDеҜ№з»„жҲҗзҡ„й“ҫжҺҘж•°жҚ®еә“гҖӮиҝҷдёӘй“ҫжҺҘж•°жҚ®еә“е“ҹеҠҹиғҪжқҘи®Ўз®—жүҖжңүж–Ү件зҡ„PageRankеҖјгҖӮ
жҺ’еәҸеҷЁ(sorter)еҜ№жҢүз…§docIDжҺ’еәҸзҡ„(иҝҷйҮҢеҒҡдәҶз®ҖеҢ–пјҢиҜҰжғ…и§Ғ4.2.5е°ҸиҠӮ)вҖңжЎ¶вҖқ(barrels)йҮҚж–°жҢүз…§wordIDжҺ’еәҸпјҢз”ЁдәҺдә§з”ҹеҖ’жҺ’зҙўеј•(inverted index)гҖӮиҝҷдёӘж“ҚдҪңеңЁжҒ°еҪ“зҡ„ж—¶еҖҷиҝӣиЎҢпјҢжүҖд»ҘйңҖиҰҒеҫҲе°‘зҡ„жҡӮеӯҳз©әй—ҙгҖӮжҺ’еәҸеҷЁиҝҳеңЁеҖ’жҺ’зҙўеј•дёӯе»әз«ӢдёҖдёӘwordIDе’ҢеҒҸ移йҮҸзҡ„еҲ—иЎЁгҖӮдёҖдёӘеҸ«DumpLexiconзҡ„зЁӢеәҸжҠҠиҝҷдёӘеҲ—иЎЁдёҺз”ұзҙўеј•еҷЁдә§з”ҹзҡ„иҜҚе…ёз»“еҗҲиө·жқҘпјҢз”ҹжҲҗдёҖдёӘж–°зҡ„иҜҚе…ёпјҢдҫӣжҗңзҙўеҷЁпјҲsearcherпјүдҪҝз”ЁгҖӮжҗңзҙўеҷЁз”ұдёҖдёӘWebжңҚеҠЎеҷЁиҝҗиЎҢпјҢж №жҚ®DumpLexiconдә§з”ҹзҡ„иҜҚе…ёпјҢеҖ’жҺ’зҙўеј•е’ҢPageRankеҖјжқҘеӣһзӯ”жҹҘиҜўгҖӮ
4.2 дё»иҰҒзҡ„ж•°жҚ®з»“жһ„
Googleзҡ„ж•°жҚ®з»“жһ„з»ҸиҝҮдәҶдјҳеҢ–пјҢиҝҷж ·еӨ§йҮҸзҡ„ж–ҮжЎЈиғҪеӨҹеңЁиҫғдҪҺзҡ„жҲҗжң¬дёӢиў«жҠ“еҸ–пјҢзҙўеј•е’ҢжҗңзҙўгҖӮе°Ҫз®ЎCPUе’ҢI/OйҖҹзҺҮиҝҷдәӣе№ҙд»ҘжғҠдәәзҡ„йҖҹеәҰеўһй•ҝпјҢдҪҶжҳҜжҜҸдёҖдёӘзЈҒзӣҳжҹҘжүҫж“ҚдҪңд»ҚйңҖиҰҒеӨ§жҰӮ10еҫ®з§’жүҚиғҪе®ҢжҲҗгҖӮGoogleеңЁи®ҫи®Ўж—¶е°ҪйҮҸйҒҝе…ҚзЈҒзӣҳжҹҘжүҫпјҢиҝҷдёҖи®ҫи®Ўд№ҹеӨ§еӨ§еҪұе“ҚдәҶж•°жҚ®з»“жһ„зҡ„и®ҫи®ЎгҖӮ
4.2.1 BigFiles
BigFilesжҳҜеҲҶеёғеңЁдёҚеҗҢж–Ү件系з»ҹдёӢйқўзҡ„иҷҡжӢҹж–Ү件пјҢйҖҡиҝҮ64дҪҚж•ҙж•°еҜ»еқҖгҖӮиҷҡжӢҹж–Ү件被иҮӘеҠЁеҲҶй…ҚеҲ°дёҚеҗҢж–Ү件系з»ҹгҖӮBigFilesзҡ„еҢ…иҝҳиҙҹиҙЈеҲҶй…Қе’ҢйҮҠж”ҫж–Ү件жҸҸиҝ°з¬ҰпјҲиҜ‘иҖ…жіЁпјҡзүөж¶үеҲ°ж“ҚдҪңзі»з»ҹеә•еұӮпјүпјҢеӣ дёәж“ҚдҪңзі»з»ҹжҸҗдҫӣзҡ„еҠҹиғҪ并дёҚиғҪж»Ўи¶іжҲ‘们зҡ„иҰҒжұӮгҖӮBigFilesиҝҳж”ҜжҢҒеҹәжң¬зҡ„еҺӢзј©йҖүйЎ№гҖӮ
4.2.2 ж•°жҚ®д»“еә“пјҲRepositoryпјү

еӣҫ2. ж•°жҚ®д»“еә“зҡ„з»“жһ„
ж•°жҚ®д»“еә“еҢ…жӢ¬дәҶжҜҸдёӘwebйЎөйқўзҡ„ж•ҙдёӘHTMLд»Јз ҒгҖӮжҜҸдёӘйЎөйқўз”ЁzlibпјҲеҸӮи§ҒRFC1950пјүеҺӢзј©гҖӮеҺӢзј©жҠҖжңҜзҡ„йҖүжӢ©жҳҜйҖҹеәҰе’ҢеҺӢзј©жҜ”зҡ„дёҖдёӘжқғиЎЎгҖӮжҲ‘们йҖүжӢ©zlibжҳҜеӣ дёәе®ғзҡ„еҺӢзј©йҖҹеәҰиҰҒжҜ”bzipеҝ«еҫҲеӨҡгҖӮеңЁж•°жҚ®д»“еә“дёҠпјҢbzipзҡ„еҺӢзј©жҜ”жҳҜ4пјҡ1пјҢиҖҢzlibзҡ„жҳҜ3пјҡ1гҖӮеңЁж•°жҚ®д»“еә“дёӯпјҢж–ҮжЎЈдёҖдёӘдёҖдёӘиҝһжҺҘеӯҳж”ҫпјҢжҜҸдёӘж–ҮжЎЈжңүдёҖдёӘеүҚзјҖпјҢеҢ…жӢ¬docIDпјҢй•ҝеәҰе’ҢURLпјҲеҰӮеӣҫ2пјүгҖӮиҰҒи®ҝй—®иҝҷдәӣж–ҮжЎЈпјҢж•°жҚ®д»“еә“дёҚеҶҚйңҖиҰҒе…¶д»–зҡ„ж•°жҚ®з»“жһ„гҖӮиҝҷдҪҝеҫ—дҝқжҢҒж•°жҚ®дёҖиҮҙжҖ§е’ҢејҖеҸ‘йғҪжӣҙз®ҖеҚ•пјӣжҲ‘们еҸҜд»Ҙд»…д»…йҖҡиҝҮж•°жҚ®д»“еә“е’ҢдёҖдёӘи®°еҪ•зҲ¬иҷ«й”ҷиҜҜдҝЎжҒҜзҡ„ж–Ү件жқҘйҮҚе»әе…¶д»–жүҖжңүзҡ„ж•°жҚ®з»“жһ„гҖӮ
4.2.3 ж–ҮжЎЈзҙўеј•пјҲDocument Indexпјү
ж–ҮжЎЈзҙўеј•дҝқеӯҳдәҶжҜҸдёӘж–ҮжЎЈзҡ„дҝЎжҒҜгҖӮе®ғжҳҜдёҖдёӘж №жҚ®docIDжҺ’еәҸзҡ„е®ҡй•ҝ(fixed width)ISAMпјҲзҙўеј•йЎәеәҸи®ҝй—®жЁЎејҸIndex sequential access modeпјүзҙўеј•гҖӮиҝҷдәӣдҝЎжҒҜиў«еӯҳж”ҫеңЁжҜҸдёӘжқЎзӣ®(entry)йҮҢйқўпјҢеҢ…жӢ¬еҪ“еүҚж–ҮжЎЈзҠ¶жҖҒпјҢжҢҮеҗ‘ж•°жҚ®д»“еә“зҡ„жҢҮй’ҲпјҢж–ҮжЎЈж ЎйӘҢе’Ң(checksum)е’Ңеҗ„з§Қз»ҹи®Ўж•°жҚ®гҖӮеҰӮжһңж–ҮжЎЈе·Із»Ҹиў«жҠ“еҸ–дәҶпјҢе®ғиҝҳдјҡеҢ…жӢ¬дёҖдёӘжҢҮй’ҲпјҢиҝҷдёӘжҢҮй’ҲжҢҮеҗ‘дёҖдёӘеҸ«docinfoзҡ„еҸҳй•ҝ(variable width)ж–Ү件пјҢйҮҢйқўи®°еҪ•дәҶж–ҮжЎЈзҡ„URLе’Ңж ҮйўҳгҖӮеҗҰеҲҷпјҢиҝҷдёӘжҢҮй’Ҳе°ҶжҢҮеҗ‘дёҖдёӘURLеҲ—иЎЁпјҢйҮҢйқўеҸӘжңүURLгҖӮиҝҷж ·и®ҫи®Ўзҡ„зӣ®зҡ„жҳҜдёәдәҶжңүдёҖдёӘзӣёеҜ№зҙ§еҮ‘зҡ„ж•°жҚ®з»“жһ„пјҢеңЁдёҖж¬Ўжҗңзҙўж“ҚдҪңдёӯеҸӘйңҖиҰҒдёҖж¬ЎзЈҒзӣҳжҹҘжүҫе°ұиғҪеҸ–еҮәдёҖжқЎи®°еҪ•гҖӮ
еҸҰеӨ–пјҢиҝҳжңүдёҖдёӘж–Ү件用жқҘе°ҶURLиҪ¬еҢ–жҲҗdocIDгҖӮиҝҷдёӘж–Ү件жҳҜдёҖдёӘеҲ—иЎЁпјҢеҢ…жӢ¬URLж ЎйӘҢе’Ң(checksum)е’ҢеҜ№еә”зҡ„docIDпјҢж №жҚ®ж ЎйӘҢе’ҢжҺ’еәҸгҖӮдёәдәҶжүҫеҲ°жҹҗдёҖдёӘURLзҡ„docIDпјҢйҰ–е…Ҳи®Ўз®—URLзҡ„ж ЎйӘҢе’ҢпјҢ然еҗҺеңЁж ЎйӘҢе’Ңж–Ү件йҮҢеҒҡдёҖж¬ЎдәҢеҲҶжҹҘжүҫпјҢжүҫеҲ°е®ғзҡ„docIDгҖӮURLиҪ¬еҢ–жҲҗdocIDжҳҜйҖҡиҝҮж–Ү件еҗҲ并жү№йҮҸж“ҚдҪңзҡ„гҖӮиҝҷдёӘжҠҖжңҜжҳҜеңЁURLеҲҶи§ЈеҷЁпјҲURL resolverпјүжҠҠURLиҪ¬еҢ–жҲҗdocIDж—¶дҪҝз”Ёзҡ„гҖӮиҝҷз§Қжү№йҮҸжӣҙж–°зҡ„жЁЎејҸеҫҲе…ій”®пјҢеӣ дёәеҰӮжһңжҲ‘们дёәжҜҸдёӘй“ҫжҺҘеҒҡдёҖж¬ЎзЈҒзӣҳжҹҘжүҫпјҢдёҖдёӘзЈҒзӣҳйңҖиҰҒ1дёӘжңҲзҡ„ж—¶й—ҙжүҚиғҪдёәжҲ‘们зҡ„3.22дәҝжқЎй“ҫжҺҘзҡ„ж•°жҚ®йӣҶе®ҢжҲҗжӣҙж–°гҖӮ
4.2.4 иҜҚе…ёпјҲLexiconпјү
иҜҚе…ёеӨҡз§ҚдёҚеҗҢж јејҸгҖӮдёҺж—©еүҚзҡ„зі»з»ҹзӣёжҜ”пјҢдёҖдёӘйҮҚиҰҒзҡ„еҸҳеҢ–жҳҜзҺ°еңЁзҡ„иҜҚе…ёеҸҜд»Ҙд»ҘеҗҲзҗҶзҡ„жҲҗжң¬е…ЁйғЁж”ҫеңЁеҶ…еӯҳйҮҢйқўгҖӮзӣ®еүҚзҡ„е®һзҺ°дёӯпјҢжҲ‘们жҠҠиҜҚе…ёж”ҫеңЁдёҖдёӘ256Mзҡ„дё»еӯҳйҮҢйқўгҖӮзҺ°еңЁзҡ„иҜҚе…ёжңү1.4еҚғдёҮеҚ•иҜҚпјҲе°Ҫз®ЎдёҖдәӣйқһеёёз”ЁиҜҚжІЎжңүиў«еҢ…еҗ«иҝӣжқҘпјүгҖӮе®ғз”ұдёӨйғЁеҲҶе®һзҺ°вҖ”вҖ”дёҖдёӘеҚ•иҜҚеҲ—иЎЁпјҲиҝһжҺҘеңЁдёҖиө·пјҢдҪҶжҳҜйҖҡиҝҮз©әзҷҪnullsеҲҶејҖпјүе’ҢдёҖдёӘжҢҮй’Ҳзҡ„е“ҲеёҢиЎЁ(hash table)гҖӮеҚ•иҜҚеҲ—иЎЁиҝҳжңүдёҖдәӣйҷ„еҠ дҝЎжҒҜпјҢдҪҶжҳҜиҝҷдәӣдёҚеңЁжң¬зҜҮж–Үз« зҡ„и®Ёи®әиҢғеӣҙгҖӮ
4.2.5 е‘ҪдёӯеҲ—иЎЁпјҲHit Listsпјү
дёҖдёӘе‘ҪдёӯеҲ—иЎЁеҜ№еә”зқҖдёҖдёӘеҚ•иҜҚеңЁдёҖдёӘж–ҮжЎЈдёӯеҮәзҺ°зҡ„дҪҚзҪ®гҖҒеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜзҡ„еҲ—иЎЁгҖӮе‘ҪдёӯеҲ—иЎЁеҚ з”ЁдәҶжӯЈжҺ’зҙўеј•е’ҢеҖ’жҺ’зҙўеј•зҡ„еӨ§йғЁеҲҶз©әй—ҙпјҢжүҖд»ҘжҖҺж ·е°ҪеҸҜиғҪжңүж•Ҳзҡ„иЎЁзӨәжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮжҲ‘们иҖғиҷ‘дәҶеҜ№дҪҚзҪ®пјҢеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜзҡ„еӨҡз§Қзј–з Ғж–№ејҸвҖ”вҖ”з®ҖеҚ•зј–з ҒпјҲ3дёӘж•ҙж•°пјүпјҢеҺӢзј©зј–з ҒпјҲжүӢе·ҘдјҳеҢ–еҲҶй…ҚжҜ”зү№пјүе’ҢйңҚеӨ«жӣјзј–з ҒпјҲHuffman codingпјүгҖӮе‘ҪдёӯпјҲhitпјүзҡ„иҜҰжғ…и§Ғеӣҫ3гҖӮ
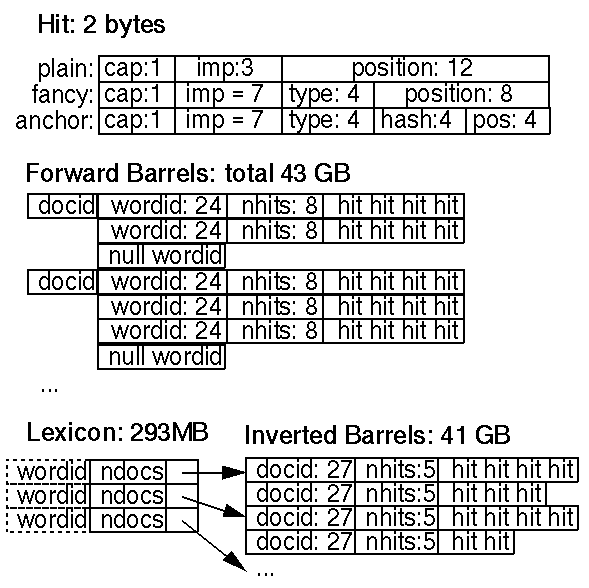
еӣҫ3. жӯЈгҖҒеҖ’жҺ’зҙўеј•е’ҢиҜҚе…ё
жҲ‘们зҡ„еҺӢзј©зј–з ҒжҜҸдёӘе‘Ҫдёӯз”ЁеҲ°дёӨдёӘеӯ—иҠӮ(byte)гҖӮжңүдёӨз§Қе‘Ҫдёӯпјҡзү№ж®Ҡе‘ҪдёӯпјҲfancy hitпјүе’Ңжҷ®йҖҡе‘ҪдёӯпјҲplain hitпјүгҖӮзү№ж®Ҡе‘ҪдёӯеҢ…жӢ¬еңЁURLпјҢж ҮйўҳпјҢй”ҡж–Үжң¬е’Ңmetaж ҮзӯҫдёҠзҡ„е‘ҪдёӯгҖӮе…¶д»–зҡ„йғҪжҳҜжҷ®йҖҡе‘ҪдёӯгҖӮдёҖдёӘжҷ®йҖҡзҡ„е‘ҪдёӯеҢ…жӢ¬дёҖдёӘиЎЁзӨәеӨ§е°ҸеҶҷзҡ„жҜ”зү№(bit)пјҢеӯ—дҪ“еӨ§е°ҸпјҢе’Ң12дёӘbitиЎЁзӨәзҡ„еҚ•иҜҚеңЁж–Ү件дёӯзҡ„дҪҚзҪ®пјҲжүҖжңүжҜ”4095еӨ§зҡ„дҪҚзҪ®йғҪиў«ж ҮзӨәдёә4096пјүгҖӮеӯ—дҪ“еңЁж–ҮжЎЈдёӯзҡ„зӣёеҜ№еӨ§е°Ҹз”Ё3дёӘжҜ”зү№иЎЁзӨәпјҲе®һйҷ…дёҠеҸӘз”ЁеҲ°7дёӘеҖјпјҢеӣ дёә111ж ҮзӨәдёҖдёӘзү№ж®Ҡе‘ҪдёӯпјүгҖӮдёҖдёӘзү№ж®Ҡе‘ҪдёӯеҢ…еҗ«дёҖдёӘеӨ§е°ҸеҶҷжҜ”зү№пјҢеӯ—дҪ“еӨ§е°Ҹи®ҫзҪ®дёә7з”ЁжқҘиЎЁзӨәе®ғжҳҜдёҖдёӘзү№ж®Ҡе‘ҪдёӯпјҢ4дёӘжҜ”зү№з”ЁжқҘиЎЁзӨәзү№ж®Ҡе‘Ҫдёӯзҡ„зұ»еһӢпјҢ8дёӘжҜ”зү№иЎЁзӨәдҪҚзҪ®гҖӮеҜ№дәҺй”ҡе‘ҪдёӯпјҢиЎЁзӨәдҪҚзҪ®зҡ„8дёӘжҜ”зү№иў«еҲҶжҲҗдёӨйғЁеҲҶпјҢ4дёӘжҜ”зү№иЎЁзӨәеңЁй”ҡж–Үжң¬дёӯзҡ„дҪҚзҪ®пјҢ4дёӘжҜ”зү№дёәй”ҡж–Үжң¬жүҖеңЁdocIDзҡ„е“ҲеёҢпјҲhashпјүеҖјгҖӮз”ұдәҺдёҖдёӘиҜҚ并没жңүйӮЈд№ҲеӨҡзҡ„й”ҡж–Үжң¬пјҢжүҖд»ҘзҹӯиҜӯжҗңзҙўеҸ—еҲ°дёҖдәӣйҷҗеҲ¶гҖӮжҲ‘们жңҹжңӣиғҪжӣҙж–°й”ҡе‘Ҫдёӯзҡ„еӯҳеӮЁж–№ејҸиғҪи®©дҪҚзҪ®е’ҢdocIDе“ҲеёҢеҖјиғҪжңүжӣҙеӨ§зҡ„иҢғеӣҙгҖӮжҲ‘们дҪҝз”ЁеңЁдёҖдёӘж–ҮжЎЈдёӯзҡ„зӣёеҜ№еӯ—дҪ“еӨ§е°ҸжҳҜеӣ дёәеңЁжҗңзҙўж—¶пјҢдҪ 并дёҚеёҢжңӣеҜ№дәҺеҶ…е®№зӣёеҗҢзҡ„дёҚеҗҢж–ҮжЎЈпјҢд»…д»…еӣ дёәдёҖдёӘж–ҮжЎЈеӯ—дҪ“жҜ”иҫғеӨ§иҖҢжңүжӣҙй«ҳзҡ„иҜ„зә§пјҲrankпјүгҖӮ
е‘ҪдёӯеҲ—иЎЁзҡ„й•ҝеәҰеӯҳеңЁе‘Ҫдёӯзҡ„еүҚйқўгҖӮдёәдәҶиҠӮзңҒз©әй—ҙпјҢе‘ҪдёӯеҲ—иЎЁзҡ„й•ҝеәҰеңЁжӯЈжҺ’зҙўеј•дёӯдёҺwordIDз»“еҗҲпјҢеңЁеҖ’жҺ’зҙўеј•дёӯдёҺdocIDз»“еҗҲгҖӮиҝҷж ·е°ұе°Ҷй•ҝеәҰеҲҶеҲ«йҷҗеҲ¶еңЁ8дёӘжҜ”зү№е’Ң5дёӘжҜ”зү№пјҲжңүдёҖдәӣжҠҖе·§еҸҜд»Ҙд»ҺwordIDдёӯеҖҹз”Ё8дёӘжҜ”зү№пјүгҖӮеҰӮжһңй•ҝеәҰи¶…иҝҮдәҶиҝҷдёӘиҢғеӣҙпјҢдјҡеңЁиҝҷдәӣжҜ”зү№дёӯдҪҝз”ЁиҪ¬д№үз ҒпјҢеңЁжҺҘдёӢжқҘзҡ„дёӨдёӘеӯ—иҠӮ(byte)йҮҢжүҚеӯҳж”ҫзңҹжӯЈзҡ„й•ҝеәҰгҖӮ
4.2.6 жӯЈжҺ’зҙўеј•пјҲForward Indexпјү
жӯЈжҺ’зҙўеј•е®һйҷ…дёҠе·Із»ҸйғЁеҲҶжҺ’еәҸпјҲpartially sortedпјүгҖӮе®ғиў«еӯҳж”ҫеңЁдёҖзі»еҲ—зҡ„жЎ¶пјҲbarrelsпјүйҮҢйқўпјҲжҲ‘们用дәҶ64дёӘпјүгҖӮжҜҸдёӘжЎ¶дҝқеӯҳдәҶдёҖе®ҡиҢғеӣҙеҶ…зҡ„wordIDгҖӮеҰӮжһңдёҖдёӘж–ҮжЎЈеҢ…еҗ«дәҶеұһдәҺжҹҗдёӘжЎ¶зҡ„еҚ•иҜҚпјҢе®ғзҡ„docIDе°Ҷиў«и®°еҪ•еңЁжЎ¶йҮҢйқўпјҢеҗҺйқўжҺҘзқҖдёҖдёӘwordIDзҡ„еҲ—иЎЁе’Ңзӣёеә”зҡ„е‘ҪдёӯеҲ—иЎЁгҖӮиҝҷз§Қз»“жһ„йңҖиҰҒдёҖзӮ№еӨҡдҪҷз©әй—ҙпјҢеӣ дёәеӯҳеӮЁдәҶйҮҚеӨҚзҡ„docIDпјҢз”ұдәҺжЎ¶зҡ„ж•°йҮҸеҫҲе°ҸпјҢжүҖд»ҘеӯҳеӮЁз©әй—ҙзҡ„е·®еҲ«еҫҲе°ҸпјҢдҪҶжҳҜе®ғиғҪеңЁжҺ’еәҸеҷЁпјҲsorterпјүе»әз«ӢжңҖз»Ҳзҙўеј•зҡ„ж—¶еҖҷеӨ§еӨ§иҠӮзңҒж—¶й—ҙ并йҷҚдҪҺдәҶзЁӢеәҸеӨҚжқӮеәҰгҖӮжӣҙиҝӣдёҖжӯҘпјҢжҲ‘们并没жңүеӯҳеӮЁе®Ңж•ҙзҡ„wordIDпјҢиҖҢжҳҜеӯҳеӮЁжҜҸдёӘwordIDзӣёеҜ№дәҺе…¶еҜ№еә”зҡ„жЎ¶йҮҢйқўжңҖе°ҸwordIDзҡ„е·®и·қгҖӮиҝҷж ·жҲ‘们еҸӘз”ЁеҲ°дәҶ24дёӘжҜ”зү№пјҢд»ҺиҖҢдёәе‘ҪдёӯеҲ—иЎЁй•ҝеәҰпјҲhit list lengthпјүз•ҷеҮәдәҶ8дёӘжҜ”зү№гҖӮ
4.2.7 еҖ’жҺ’зҙўеј•пјҲInverted Indexпјү
еҖ’жҺ’зҙўеј•дёҺжӯЈжҺ’зҙўеј•жңүзқҖзӣёеҗҢзҡ„жЎ¶пјҢдҪҶжҳҜе®ғ们жҳҜе…Ҳз»ҸиҝҮжҺ’еәҸеҷЁеӨ„зҗҶиҝҮзҡ„гҖӮеҜ№жҜҸдёҖдёӘеҗҲжі•зҡ„wordIDпјҢиҜҚе…ёеҢ…еҗ«дәҶдёҖдёӘжҢҮеҗ‘еҜ№еә”зҡ„жЎ¶зҡ„жҢҮй’ҲгҖӮе®ғжҢҮеҗ‘дёҖдёӘdocIDзҡ„еҲ—иЎЁе’Ңзӣёеә”зҡ„е‘ҪдёӯеҲ—иЎЁгҖӮиҝҷдёӘж–ҮжЎЈеҲ—иЎЁжҳҫзӨәдәҶжңүиҝҷдёӘеҚ•иҜҚеҮәзҺ°зҡ„жүҖжңүж–ҮжЎЈгҖӮ
дёҖдёӘйҮҚиҰҒзҡ„дәӢжғ…жҳҜеҰӮдҪ•еҜ№иҝҷдёӘж–ҮжЎЈеҲ—иЎЁжҺ’еәҸгҖӮдёҖдёӘз®ҖеҚ•зҡ„ж–№жі•жҳҜжҢүз…§docIDжҺ’еәҸгҖӮеңЁеӨҡдёӘеҚ•иҜҚзҡ„жҹҘиҜўдёӯпјҢиҝҷз§Қж–№жі•еҸҜд»Ҙеҝ«йҖҹең°е®ҢжҲҗдёӨдёӘж–ҮжЎЈеҲ—иЎЁзҡ„еҪ’并гҖӮеҸҰдёҖз§Қж–№жЎҲжҳҜжҢүз…§иҝҷдёӘиҜҚеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„иҜ„еҲҶ(ranking)жҺ’еәҸгҖӮиҝҷз§Қж–№ејҸдҪҝеҫ—еҚ•дёӘиҜҚзҡ„жҹҘиҜўзӣёеҪ“з®ҖеҚ•пјҢ并且еӨҡиҜҚжҹҘиҜўзҡ„иҝ”еӣһз»“жһңд№ҹеҫҲеҸҜиғҪжҺҘиҝ‘ејҖеӨҙпјҲиҜ‘иҖ…жіЁпјҡиҝҷеҸҘдёҚжҳҜеҫҲзҗҶи§ЈпјүгҖӮдҪҶжҳҜпјҢеҪ’并иҰҒеӣ°йҡҫеҫ—еӨҡгҖӮиҖҢдё”пјҢејҖеҸ‘д№ҹдјҡеӣ°йҡҫеҫ—еӨҡпјҢеӣ дёәжҜҸж¬ЎиҜ„еҲҶеҮҪж•°еҸҳеҠЁе°ұйңҖиҰҒйҮҚж–°е»әз«Ӣж•ҙдёӘзҙўеј•гҖӮжҲ‘们综еҗҲдәҶдёӨз§Қж–№жЎҲпјҢи®ҫи®ЎдәҶдёӨдёӘеҖ’жҺ’жЎ¶йӣҶеҗҲвҖ”вҖ”дёҖдёӘйӣҶеҗҲеҸӘеҢ…жӢ¬ж Үйўҳе’Ңй”ҡе‘ҪдёӯпјҲиҜ‘иҖ…жіЁпјҡеҗҺйқўз®Җз§°зҹӯжЎ¶пјүпјҢеҸҰдёҖдёӘйӣҶеҗҲеҢ…еҗ«жүҖжңүзҡ„е‘ҪдёӯпјҲиҜ‘иҖ…жіЁпјҡеҗҺйқўз®Җз§°е…ЁжЎ¶пјүгҖӮиҝҷж ·жҲ‘们йҰ–е…ҲжЈҖжҹҘ第дёҖдёӘжЎ¶йӣҶеҗҲпјҢеҰӮжһңжІЎжңүи¶іеӨҹзҡ„еҢ№й…ҚеҶҚжЈҖжҹҘйӮЈдёӘеӨ§дёҖзӮ№зҡ„гҖӮ
4.3 зҪ‘йЎөжҠ“еҸ–пјҲCrawling the Webпјү
иҝҗиЎҢзҪ‘з»ңзҲ¬иҷ«жҳҜдёҖйЎ№еҫҲжңүжҢ‘жҲҳжҖ§зҡ„д»»еҠЎгҖӮиҝҷйҮҢдёҚе…үж¶үеҸҠеҲ°е·§еҰҷзҡ„жҖ§иғҪе’ҢеҸҜйқ жҖ§й—®йўҳпјҢжӣҙйҮҚиҰҒзҡ„пјҢиҝҳжңүзӨҫдјҡй—®йўҳгҖӮжҠ“еҸ–жҳҜдёҖдёӘеҫҲи„Ҷејұзҡ„еә”з”ЁпјҢеӣ дёәе®ғйңҖиҰҒдёҺжҲҗзҷҫдёҠеҚғеҗ„з§Қеҗ„ж ·зҡ„webжңҚеҠЎеҷЁе’ҢеҹҹеҗҚжңҚеҠЎеҷЁдәӨдә’пјҢиҝҷдәӣйғҪдёҚеңЁзі»з»ҹзҡ„жҺ§еҲ¶иҢғеӣҙд№ӢеҶ…гҖӮ
дёәдәҶжҠ“еҸ–еҮ дәҝзҪ‘йЎөпјҢGoogleжңүдёҖдёӘеҝ«йҖҹзҡ„еҲҶеёғејҸзҲ¬иҷ«зі»з»ҹгҖӮдёҖдёӘеҚ•зӢ¬зҡ„URLжңҚеҠЎеҷЁпјҲURLserverпјүдёәеӨҡдёӘзҲ¬иҷ«(crawler,дёҖиҲ¬жҳҜ3дёӘ)жҸҗдҫӣURLеҲ—иЎЁгҖӮURLжңҚеҠЎеҷЁе’ҢзҲ¬иҷ«йғҪз”ЁPythonе®һзҺ°гҖӮжҜҸдёӘзҲ¬иҷ«еҗҢж—¶жү“ејҖеӨ§жҰӮ300дёӘиҝһжҺҘ(connecton)гҖӮиҝҷж ·жүҚиғҪдҝқиҜҒи¶іеӨҹеҝ«ең°жҠ“еҸ–йҖҹеәҰгҖӮеңЁй«ҳеі°ж—¶жңҹпјҢзі»з»ҹйҖҡиҝҮ4дёӘзҲ¬иҷ«жҜҸз§’й’ҹзҲ¬еҸ–100дёӘзҪ‘йЎөгҖӮиҝҷеӨ§жҰӮжңү600KжҜҸз§’зҡ„ж•°жҚ®дј иҫ“гҖӮдёҖдёӘдё»иҰҒзҡ„жҖ§иғҪеҺӢеҠӣеңЁDNSжҹҘиҜў(lookup)гҖӮжҜҸдёӘзҲ¬иҷ«йғҪз»ҙжҠӨдёҖдёӘиҮӘе·ұзҡ„DNSзј“еӯҳпјҢиҝҷж ·еңЁе®ғжҠ“еҸ–зҪ‘йЎөд№ӢеүҚе°ұдёҚеҶҚйңҖиҰҒжҜҸж¬ЎйғҪеҒҡDNSжҹҘиҜўгҖӮеҮ зҷҫдёӘиҝһжҺҘеҸҜиғҪеӨ„дәҺдёҚеҗҢзҡ„зҠ¶жҖҒпјҡжҹҘиҜўDNSпјҢиҝһжҺҘдё»жңәпјҢеҸ‘йҖҒиҜ·жұӮпјҢжҺҘеҸ—е“Қеә”гҖӮиҝҷдәӣеӣ зҙ дҪҝеҫ—зҲ¬иҷ«жҲҗдёәзі»з»ҹйҮҢдёҖдёӘеӨҚжқӮзҡ„жЁЎеқ—гҖӮе®ғз”ЁејӮжӯҘIOжқҘз®ЎзҗҶдәӢ件пјҢз”ЁдёҖдәӣйҳҹеҲ—жқҘз®ЎзҗҶйЎөйқўжҠ“еҸ–зҡ„зҠ¶жҖҒгҖӮ
дәӢе®һиҜҒжҳҺпјҢзҲ¬иҷ«иҝһжҺҘдәҶ50еӨҡдёҮдёӘжңҚеҠЎеҷЁпјҢдә§з”ҹдәҶеҮ еҚғдёҮжқЎж—Ҙеҝ—дҝЎжҒҜпјҢдјҡеёҰжқҘеӨ§йҮҸзҡ„з”өеӯҗйӮ®д»¶е’Ңз”өиҜқгҖӮеӣ дёәеҫҲеӨҡдәәеңЁзҪ‘дёҠпјҢ他们并дёҚзҹҘйҒ“зҲ¬иҷ«жҳҜд»Җд№ҲпјҢеӣ дёәиҝҷжҳҜ他们第дёҖж¬Ўи§ҒеҲ°гҖӮеҮ д№ҺжҜҸеӨ©пјҢжҲ‘们йғҪдјҡ收еҲ°иҝҷж ·зҡ„з”өеӯҗйӮ®д»¶пјҡвҖңе“ҮпјҢдҪ зңӢдәҶеҘҪеӨҡжҲ‘з«ҷдёҠзҡ„йЎөйқўпјҢдҪ и§үеҫ—жҖҺд№Ҳж ·пјҹвҖқд№ҹжңүеҫҲеӨҡдәә并дёҚзҹҘйҒ“зҲ¬иҷ«зҰҒз”ЁеҚҸи®®пјҲrobots exclusion protocolпјүпјҢ他们и®ӨдёәеҸҜд»ҘйҖҡиҝҮеңЁйЎөйқўдёҠеЈ°жҳҺвҖңжң¬йЎөйқўеҸ—зүҲжқғдҝқжҠӨпјҢжӢ’з»қзҙўеј•вҖқе°ұеҸҜд»ҘдҝқжҠӨйЎөйқўпјҢдёҚз”ЁиҜҙпјҢзҪ‘з»ңзҲ¬иҷ«еҫҲйҡҫзҗҶи§Јиҝҷж ·зҡ„иҜқгҖӮиҖҢдё”пјҢз”ұдәҺж¶үеҸҠеҲ°еӨ§йҮҸзҡ„ж•°жҚ®пјҢдёҖдәӣж„ҸжғідёҚеҲ°зҡ„дәӢжғ…жҖ»дјҡеҸ‘з”ҹгҖӮжҜ”еҰӮпјҢжҲ‘们зҡ„зі»з»ҹиҜ•еӣҫеҺ»жҠ“еҸ–дёҖдёӘеңЁзәҝжёёжҲҸгҖӮиҝҷеҜјиҮҙдәҶжёёжҲҸдёӯеҮәзҺ°еӨ§йҮҸзҡ„еһғеңҫж¶ҲжҒҜпјҒиҝҷдёӘй—®йўҳиў«иҜҒе®һжҳҜеҫҲе®№жҳ“и§ЈеҶізҡ„гҖӮдҪҶжҳҜеҫҖеҫҖжҲ‘们еңЁдёӢиҪҪдәҶеҮ еҚғдёҮдёӘйЎөйқўд№ӢеҗҺиҝҷдёӘй—®йўҳжүҚиў«еҸ‘зҺ°гҖӮеӣ дёәзҪ‘з»ңйЎөйқўе’ҢжңҚеҠЎеҷЁжҖ»жҳҜеңЁеҸҳеҢ–дёӯпјҢеңЁзҲ¬иҷ«жӯЈејҸиҝҗиЎҢеңЁеӨ§йғЁеҲҶзҡ„дә’иҒ”зҪ‘з«ҷзӮ№д№ӢеүҚжҳҜдёҚеҸҜиғҪиҝӣиЎҢжөӢиҜ•зҡ„гҖӮдёҚеҸҳзҡ„жҳҜпјҢжҖ»жңүдёҖдәӣеҘҮжҖӘзҡ„й”ҷиҜҜеҸӘдјҡеңЁдёҖдёӘйЎөйқўйҮҢйқўеҮәзҺ°пјҢ并且еҜјиҮҙзҲ¬иҷ«еҙ©жәғпјҢжҲ–иҖ…жӣҙеқҸпјҢеҜјиҮҙдёҚеҸҜйў„жөӢзҡ„жҲ–иҖ…й”ҷиҜҜзҡ„иЎҢдёәгҖӮйңҖиҰҒи®ҝй—®еӨ§йҮҸдә’иҒ”зҪ‘з«ҷзӮ№зҡ„зі»з»ҹйңҖиҰҒи®ҫи®Ўеҫ—еҫҲеҒҘ壮并且е°Ҹеҝғең°жөӢиҜ•гҖӮеӣ дёәеӨ§йҮҸеғҸзҲ¬иҷ«иҝҷж ·зҡ„зі»з»ҹжҢҒз»ӯеҜјиҮҙй—®йўҳпјҢжүҖд»ҘйңҖиҰҒеӨ§йҮҸзҡ„дәәеҠӣдё“й—Ёйҳ…иҜ»з”өеӯҗйӮ®д»¶пјҢеӨ„зҗҶж–°еҮәзҺ°йҒҮеҲ°зҡ„й—®йўҳгҖӮ
4.4 зҪ‘з«ҷзҙўеј•пјҲIndexing the Webпјү
и§ЈжһҗвҖ”вҖ”д»»дҪ•иў«и®ҫи®ЎжқҘи§Јжһҗж•ҙдёӘдә’иҒ”зҪ‘зҡ„и§ЈжһҗеҷЁйғҪеҝ…йЎ»еӨ„зҗҶеӨ§йҮҸеҸҜиғҪзҡ„й”ҷиҜҜгҖӮд»ҺHTMLж ҮзӯҫйҮҢйқўзҡ„й”ҷеҲ«еӯ—еҲ°дёҖдёӘж ҮзӯҫйҮҢйқўдёҠеҚғеӯ—иҠӮзҡ„0пјҢйқһASCIIеӯ—з¬ҰпјҢеөҢеҘ—дәҶеҮ зҷҫеұӮзҡ„HTMLж ҮзӯҫпјҢиҝҳжңүеӨ§йҮҸи¶…д№ҺдәәжғіиұЎзҡ„й”ҷиҜҜе’ҢвҖңеҲӣж„ҸвҖқгҖӮдёәдәҶиҫҫеҲ°жңҖеҝ«зҡ„йҖҹеәҰпјҢжҲ‘们没жңүдҪҝз”ЁYACCдә§з”ҹCFGпјҲcontext free grammaпјҢдёҠдёӢж–Үж— е…іж–Үжі•пјүи§ЈжһҗеҷЁпјҢиҖҢжҳҜз”Ёflexй…ҚеҗҲе®ғиҮӘе·ұзҡ„ж Ҳз”ҹжҲҗдәҶдёҖдёӘиҜҚжі•еҲҶжһҗеҷЁгҖӮејҖеҸ‘иҝҷж ·дёҖдёӘи§ЈжһҗеҷЁйңҖиҰҒеӨ§йҮҸзҡ„е·ҘдҪңжүҚиғҪдҝқиҜҒе®ғзҡ„йҖҹеәҰе’ҢеҒҘеЈ®гҖӮ
дёәж–ҮжЎЈе»әз«ӢжЎ¶зҙўеј•вҖ”вҖ”жҜҸдёҖдёӘж–ҮжЎЈи§ЈжһҗиҝҮеҗҺпјҢзј–з Ғеӯҳе…ҘжЎ¶йҮҢйқўгҖӮжҜҸдёҖдёӘеҚ•иҜҚиў«еҶ…еӯҳйҮҢзҡ„е“ҲеёҢиЎЁвҖ”вҖ”иҜҚе…ёиҪ¬еҢ–жҲҗдёҖдёӘwordIDгҖӮиҜҚе…ёе“ҲеёҢиЎЁж–°еҠ зҡ„еҶ…е®№йғҪиў«и®°еҪ•еңЁдёҖдёӘж–Ү件йҮҢгҖӮеҚ•иҜҚеңЁиў«иҪ¬еҢ–жҲҗжҲ‘wordIDзҡ„ж—¶еҖҷпјҢ他们еңЁеҪ“еүҚж–ҮжЎЈдёӯзҡ„еҮәзҺ°дјҡиў«зҝ»иҜ‘жҲҗе‘ҪдёӯеҲ—иЎЁпјҢ并еҶҷе…ҘжӯЈжҺ’жЎ¶(forward barrels)дёӯгҖӮе»әз«Ӣзҙўеј•йҳ¶ж®өзҡ„并иЎҢж“ҚдҪңдё»иҰҒзҡ„еӣ°йҡҫеңЁдәҺиҜҚе…ёйңҖиҰҒе…ұдә«гҖӮжҲ‘们并没жңүе…ұдә«ж•ҙдёӘиҜҚе…ёпјҢиҖҢжҳҜеңЁеҶ…еӯҳйҮҢдҝқеӯҳдёҖд»Ҫеҹәжң¬иҜҚе…ёпјҢеӣәе®ҡзҡ„1еҚғ4зҷҫдёҮдёӘеҚ•иҜҚпјҢеӨҡдҪҷзҡ„иҜҚеҶҷе…ҘдёҖдёӘж—Ҙеҝ—ж–Ү件гҖӮиҝҷж ·пјҢеӨҡдёӘзҙўеј•еҷЁе°ұеҸҜд»ҘеҗҢж—¶иҝҗиЎҢпјҢжңҖеҗҺз”ұдёҖдёӘзҙўеј•еҷЁжқҘеӨ„зҗҶиҝҷдёӘи®°еҪ•зқҖеӨҡдҪҷеҚ•иҜҚзҡ„е°Ҹж—Ҙеҝ—ж–Ү件гҖӮ
жҺ’еәҸвҖ”вҖ”дёәдәҶдә§з”ҹеҖ’жҺ’зҙўеј•пјҢжҺ’еәҸеҷЁеҸ–еҮәеҗ„дёӘжӯЈжҺ’зҡ„жЎ¶пјҢ然еҗҺж №жҚ®wordIDжҺ’еәҸжқҘдә§з”ҹдёҖдёӘж Үйўҳе’Ңй”ҡе‘Ҫдёӯзҡ„еҖ’жҺ’жЎ¶пјҢе’ҢдёҖдёӘе…Ёж–Үзҡ„еҖ’жҺ’жЎ¶гҖӮжҜҸж¬ЎеӨ„зҗҶдёҖдёӘжЎ¶пјҢжүҖд»ҘйңҖиҰҒзҡ„жҡӮеӯҳз©әй—ҙеҫҲе°‘гҖӮиҖҢдё”пјҢжҲ‘们з®ҖеҚ•ең°йҖҡиҝҮз”Ёе°ҪеҸҜиғҪеӨҡзҡ„жңәеҷЁиҝҗиЎҢеӨҡдёӘжҺ’еәҸеҷЁеҒҡеҲ°жҺ’еәҸзҡ„并иЎҢеҢ–пјҢдёҚеҗҢзҡ„жҺ’еәҸеҷЁеҸҜд»ҘеҗҢж—¶еӨ„зҗҶдёҚеҗҢзҡ„жЎ¶гҖӮеӣ дёә桶并дёҚиғҪе…ЁйғЁж”ҫеңЁдё»еӯҳйҮҢйқўпјҢжҺ’еәҸеҷЁдјҡж №жҚ®wordIDе’ҢdocIDе°Ҷе®ғ们иҝӣдёҖжӯҘеҲҶеүІжҲҗеҸҜд»Ҙж”ҫеңЁеҶ…еӯҳйҮҢйқўзҡ„жЎ¶(basket)гҖӮжҺҘзқҖпјҢжҺ’еәҸеҷЁе°ҶжҜҸдёӘжЎ¶иҪҪе…ҘеҶ…еӯҳпјҢжҺ’еҘҪеәҸпјҢжҠҠеҶ…е®№еҶҷе…Ҙзҹӯзҡ„еҖ’жҺ’жЎ¶е’Ңе®Ңж•ҙзҡ„еҖ’жҺ’жЎ¶гҖӮ
4.5 жҗңзҙўпјҲSearchingпјү
жҗңзҙўзҡ„зӣ®ж ҮжҳҜй«ҳж•Ҳең°иҝ”еӣһй«ҳиҙЁйҮҸзҡ„з»“жһңгҖӮеҫҲеӨҡеӨ§еһӢзҡ„е•Ҷдёҡжҗңзҙўеј•ж“ҺеңЁж•ҲзҺҮж–№йқўзңӢиө·жқҘйғҪжңүеҫҲеӨ§зҡ„иҝӣжӯҘгҖӮжүҖд»ҘжҲ‘们жӣҙдё“жіЁдәҺжҗңзҙўз»“жһңзҡ„иҙЁйҮҸпјҢдҪҶжҳҜжҲ‘们зӣёдҝЎжҲ‘们зҡ„и§ЈеҶіж–№жЎҲеҸӘиҰҒиҠұдёҖзӮ№зІҫеҠӣе°ұеҸҜд»ҘеҫҲеҘҪзҡ„еә”з”ЁеҲ°е•Ҷдёҡзҡ„ж•°жҚ®дёҠгҖӮGoogleзҡ„жҹҘиҜўиҜ„дј°жөҒзЁӢеҰӮеӣҫ4гҖӮ
дёәдәҶйҷҗеҲ¶е“Қеә”ж—¶й—ҙпјҢдёҖж—ҰжҹҗдёӘж•°йҮҸ(зҺ°еңЁжҳҜ40,000)зҡ„еҢ№й…Қж–ҮжЎЈиў«жүҫеҲ°пјҢжҗңзҙўеҷЁиҮӘеҠЁи·іеҲ°еӣҫ4дёӯзҡ„第8жӯҘгҖӮиҝҷж„Ҹе‘ізқҖжңүеҸҜиғҪиҝ”еӣһж¬Ўдјҳзҡ„з»“жһңгҖӮжҲ‘们зҺ°еңЁеңЁз ”究新зҡ„ж–№жі•жқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮеңЁиҝҮеҺ»пјҢжҲ‘д»¬ж №жҚ®PageRankеҖјжҺ’еәҸпјҢжңүиҫғеҘҪзҡ„ж•ҲжһңгҖӮ
и§ЈжһҗжҹҘиҜўпјҲQueryпјүгҖӮ
жҠҠеҚ•иҜҚиҪ¬еҢ–жҲҗwordIDгҖӮ
д»ҺжҜҸдёӘеҚ•иҜҚзҡ„зҹӯжЎ¶ж–ҮжЎЈеҲ—иЎЁејҖе§ӢжҹҘжүҫгҖӮ
жү«жҸҸж–ҮжЎЈеҲ—иЎЁзӣҙеҲ°жңүдёҖдёӘж–ҮжЎЈеҢ№й…ҚдәҶжүҖжңүзҡ„жҗңзҙўиҜҚиҜӯгҖӮ
и®Ўз®—иҝҷдёӘж–ҮжЎЈеҜ№еә”дәҺжҹҘиҜўзҡ„иҜ„еҲҶгҖӮ
еҰӮжһңжҲ‘们еҲ°иҫҫзҹӯжЎ¶зҡ„ж–ҮжЎЈеҲ—иЎЁз»“е°ҫпјҢд»ҺжҜҸдёӘеҚ•иҜҚзҡ„е…ЁжЎ¶(full barrel)ж–ҮжЎЈеҲ—иЎЁејҖе§ӢжҹҘжүҫпјҢи·іеҲ°з¬¬4жӯҘгҖӮ
еҰӮжһңжҲ‘们没жңүеҲ°иҫҫд»»дҪ•ж–ҮжЎЈеҲ—иЎЁзҡ„з»“е°ҫпјҢи·іеҲ°з¬¬4жӯҘгҖӮ
ж №жҚ®иҜ„еҲҶеҜ№еҢ№й…Қзҡ„ж–ҮжЎЈжҺ’еәҸпјҢ然еҗҺиҝ”еӣһиҜ„еҲҶжңҖй«ҳзҡ„kдёӘгҖӮ
еӣҫ4 GoogleжҹҘиҜўиҜ„дј°
4.5.1 иҜ„еҲҶзі»з»ҹпјҲThe Ranking Systemпјү
GoogleжҜ”е…ёеһӢзҡ„жҗңзҙўеј•ж“Һз»ҙжҠӨдәҶж №еӨҡзҡ„webж–ҮжЎЈзҡ„дҝЎжҒҜгҖӮжҜҸдёҖдёӘе‘ҪдёӯеҲ—иЎЁпјҲhitlistпјүеҢ…еҗ«дәҶдҪҚзҪ®пјҢеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜгҖӮиҖҢдё”пјҢжҲ‘们综еҗҲиҖғиҷ‘дәҶй”ҡж–Үжң¬е‘Ҫдёӯе’ҢйЎөйқўзҡ„PageRankеҖјгҖӮжҠҠжүҖжңүзҡ„дҝЎжҒҜз»јеҗҲжҲҗдёҖдёӘиҜ„еҲҶжҳҜеҫҲеӣ°йҡҫзҡ„гҖӮжҲ‘们и®ҫи®ЎдәҶиҜ„еҲҶеҮҪж•°дҝқиҜҒжІЎжңүдёҖдёӘеӣ зҙ жңүеӨӘеӨ§зҡ„еҪұе“ҚгҖӮйҰ–е…ҲпјҢиҖғиҷ‘з®ҖеҚ•зҡ„жғ…еҶөвҖ”вҖ”дёҖдёӘеҚ•иҜҚзҡ„жҹҘиҜўгҖӮдёәдәҶеҜ№дёҖдёӘеҚ•иҜҚзҡ„жҹҘиҜўи®Ўз®—ж–ҮжЎЈзҡ„еҲҶеҖјпјҢGoogleйҰ–е…ҲдёәиҝҷдёӘеҚ•иҜҚжҹҘзңӢиҝҷдёӘж–ҮжЎЈзҡ„е‘ҪдёӯеҲ—иЎЁгҖӮGoogleе°Ҷе‘ҪдёӯеҲҶдёәдёҚеҗҢзұ»еһӢпјҲж ҮйўҳпјҢй”ҡпјҢURLпјҢжҷ®йҖҡж–Үжң¬еӨ§еӯ—дҪ“пјҢжҷ®йҖҡж–Үжң¬е°Ҹеӯ—дҪ“пјҢвҖҰвҖҰпјүпјҢжҜҸдёҖз§Қзұ»еһӢйғҪжңүиҮӘе·ұзҡ„зұ»еһӢжқғйҮҚеҖјпјҲtype-weightпјүгҖӮзұ»еһӢжқғйҮҚеҖјжһ„жҲҗдёҖдёӘз”ұзұ»еһӢеҜ»еқҖпјҲindexedпјүзҡ„еҗ‘йҮҸгҖӮGoogleж•°еҮәе‘ҪдёӯеҲ—иЎЁдёӯжҜҸз§Қзұ»еһӢе‘Ҫдёӯзҡ„ж•°йҮҸгҖӮжҜҸдёӘж•°йҮҸиҪ¬еҢ–жҲҗдёҖдёӘж•°йҮҸжқғйҮҚпјҲcount-weightпјүгҖӮж•°йҮҸжқғйҮҚејҖе§ӢйҡҸзқҖж•°йҮҸзәҝжҖ§еўһй•ҝпјҢдҪҶжҳҜеҫҲеҝ«еҒңжӯўеўһй•ҝпјҢд»ҘдҝқиҜҒеҚ•иҜҚе‘Ҫдёӯж•°еӨҡдәҺжҹҗдёӘж•°йҮҸд№ӢеҗҺеҜ№жқғйҮҚдёҚеҶҚжңүеҪұе“ҚгҖӮжҲ‘们йҖҡиҝҮж•°йҮҸжқғйҮҚеҗ‘йҮҸе’Ңзұ»еһӢжқғйҮҚеҗ‘йҮҸзҡ„зӮ№д№ҳдёәдёҖдёӘж–ҮжЎЈз®—еҮәдёҖдёӘIRеҲҶж•°гҖӮжңҖеҗҺиҝҷдёӘIRеҲҶж•°дёҺPageRankз»јеҗҲдә§з”ҹиҝҷдёӘж–ҮжЎЈжңҖз»Ҳзҡ„иҜ„еҲҶгҖӮ
еҜ№дәҺдёҖдёӘеӨҡиҜҚжҗңзҙўпјҢжғ…еҶөиҰҒжӣҙеӨҚжқӮгҖӮзҺ°еңЁпјҢеӨҡдёӘе‘ҪдёӯеҲ—иЎЁеҝ…йЎ»дёҖж¬Ўжү«жҸҸе®ҢпјҢиҝҷж ·дёҖдёӘж–ҮжЎЈдёӯиҫғиҝ‘зҡ„е‘ҪдёӯжүҚиғҪжҜ”зӣёи·қиҫғиҝңзҡ„е‘Ҫдёӯжңүжӣҙй«ҳзҡ„иҜ„еҲҶгҖӮеӨҡдёӘе‘ҪдёӯеҲ—иЎЁйҮҢзҡ„е‘Ҫдёӯз»“еҗҲиө·жқҘжүҚиғҪеҢ№й…ҚеҮәзӣёйӮ»зҡ„е‘ҪдёӯгҖӮеҜ№жҜҸдёҖдёӘе‘Ҫдёӯзҡ„еҢ№й…ҚйӣҶ(matched set)пјҢдјҡи®Ўз®—еҮәдёҖдёӘжҺҘиҝ‘еәҰгҖӮжҺҘиҝ‘еәҰжҳҜеҹәдәҺдёӨдёӘе‘ҪдёӯеңЁж–ҮжЎЈпјҲжҲ–й”ҡж–Үжң¬пјүдёӯзӣёйҡ”еӨҡиҝңи®Ўз®—зҡ„пјҢдҪҶжҳҜиў«еҲҶдёә10дёӘзӯүзә§д»ҺзҹӯиҜӯеҢ№й…ҚеҲ°вҖңдёҖзӮ№йғҪдёҚиҝ‘вҖқгҖӮдёҚе…үиҰҒдёәжҜҸдёҖз§Қзұ»еһӢзҡ„е‘Ҫдёӯи®Ўж•°пјҢиҝҳиҰҒдёәжҜҸдёҖз§Қзұ»еһӢе’ҢжҺҘиҝ‘еәҰйғҪи®Ўж•°гҖӮжҜҸдёҖдёӘзұ»еһӢе’ҢжҺҘиҝ‘еәҰзҡ„з»„жңүдёҖдёӘзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚпјҲtype-prox-weightпјүгҖӮж•°йҮҸиў«иҪ¬еҢ–жҲҗж•°йҮҸжқғйҮҚгҖӮжҲ‘们йҖҡиҝҮеҜ№ж•°йҮҸжқғйҮҚе’Ңзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚеҒҡзӮ№д№ҳи®Ўз®—еҮәIRеҲҶеҖјгҖӮжүҖжңүиҝҷдәӣж•°еӯ—е’Ңзҹ©йҳөйғҪдјҡеңЁзү№ж®Ҡзҡ„и°ғиҜ•жЁЎејҸдёӢдёҺжҗңзҙўз»“жһңдёҖиө·жҳҫзӨәеҮәжқҘгҖӮиҝҷдәӣжҳҫзӨәз»“жһңеңЁејҖеҸ‘иҜ„еҲҶзі»з»ҹзҡ„ж—¶еҖҷеҫҲжңүеё®еҠ©гҖӮ
4.5.2 еҸҚйҰҲпјҲFeedbackпјү
иҜ„еҲҶеҮҪж•°жңүеҫҲеӨҡеҸӮж•°жҜ”еҰӮзұ»еһӢжқғйҮҚе’Ңзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚгҖӮжүҫеҮәиҝҷдәӣеҸӮж•°зҡ„жқғйҮҚеҖјз®Җзӣҙе°ұи·ҹеҰ–жңҜдёҖж ·гҖӮдёәдәҶи°ғж•ҙиҝҷдәӣеҸӮж•°пјҢжҲ‘们еңЁжҗңзҙўеј•ж“ҺйҮҢжңүдёҖдёӘз”ЁжҲ·еҸҚйҰҲжңәеҲ¶гҖӮдёҖдёӘиў«дҝЎд»»зҡ„з”ЁжҲ·еҸҜд»ҘйҖүжӢ©жҖ§ең°иҜ„д»·жүҖжңүзҡ„иҝ”еӣһз»“жһңгҖӮиҝҷдёӘеҸҚйҰҲиў«и®°еҪ•дёӢжқҘгҖӮ然еҗҺеңЁжҲ‘们改еҸҳиҜ„еҲҶзі»з»ҹзҡ„ж—¶еҖҷпјҢжҲ‘们иғҪзңӢеҲ°дҝ®ж”№еҜ№д№ӢеүҚиҜ„д»·иҝҮзҡ„жҗңзҙўз»“жһңзҡ„еҪұе“ҚгҖӮе°Ҫз®Ўиҝҷж ·е№¶дёҚе®ҢзҫҺпјҢдҪҶжҳҜиҝҷд№ҹз»ҷжҲ‘们дёҖдәӣж”№еҸҳиҜ„еҲҶеҮҪж•°жқҘеҪұе“Қжҗңзҙўз»“жһңзҡ„жғіжі•гҖӮ
5 з»“жһңдёҺиЎЁзҺ°
иЎЎйҮҸдёҖдёӘжҗңзҙўеј•ж“ҺжңҖйҮҚиҰҒзҡ„ж ҮеҮҶжҳҜе…¶жҗңзҙўз»“жһңзҡ„иҙЁйҮҸгҖӮиҷҪ然еҰӮдҪ•еҒҡдёҖдёӘе®Ңж•ҙзҡ„з”ЁжҲ·иҜ„дј°и¶…и¶ҠдәҶжң¬ж–Үзҡ„иҢғеӣҙпјҢдҪҶжҳҜжҲ‘们еңЁGoogleиә«дёҠеҫ—еҲ°зҡ„з»ҸйӘҢпјҢиЎЁжҳҺе®ғжҸҗдҫӣз»“жһңпјҢжҜ”дё»иҰҒе•Ҷз”Ёжҗңзҙўеј•ж“ҺеҜ№з»қеӨ§еӨҡж•°жҗңзҙўжҸҗдҫӣзҡ„з»“жһңжӣҙеҘҪгҖӮеӣҫиЎЁ4 иЎЁзӨәзҡ„ GoogleеҜ№дәҺжҗңзҙўвҖңжҜ”е°”.е…Ӣжһ—йЎҝвҖқзҡ„з»“жһңпјҢдҪңдёәдёҖдёӘдҫӢеӯҗеҸҜд»ҘиҜҙжҳҺпјҢеҜ№PageRank, anchor text пјҲе…ій”®иҜҚпјү,е’ҢproximityпјҲзӣёдјјеәҰпјүзҡ„дҪҝз”ЁгҖӮиҝҷж ·зҡ„жҗңзҙўз»“жһңжҳҫзӨәдәҶGoogleзҡ„зү№иүІгҖӮжҗңзҙўз»“жһңиў«жңҚеҠЎеҷЁдёІиҒ”еңЁдёҖиө·гҖӮиҝҷж ·зҡ„ж–№жі•еҪ“еңЁйңҖиҰҒеҜ№з»“жһңйӣҶзӯӣйҖүж—¶йқһеёёжңүз”ЁгҖӮеҫҲеӨ§ж•°йҮҸзҡ„з»“жһңдјҡжқҘиҮӘеҹҹеҗҚwhitehouse.govпјҢжңүзҗҶз”ұзӣёдҝЎиҝҷдёӘжқҘжәҗеҗ«жңүжң¬ж¬ЎиҜҘжҗңзҙўдёӯиў«жңҹжңӣжүҫеҲ°зҡ„з»“жһңгҖӮеҪ“еүҚпјҢз»қеӨ§еӨҡж•°дё»иҰҒзҡ„е•Ҷз”Ёжҗңзҙўеј•ж“ҺдёҚдјҡиҝ”еӣһд»»дҪ•жқҘиҮӘwhitehouse.govзҡ„з»“жһңпјҢжӣҙдёҚз”ЁиҜҙжӯЈзЎ®зҡ„з»“жһңгҖӮжіЁж„ҸпјҢ第дёҖдёӘжҗңзҙўеҲ°зҡ„иҝһжҺҘжІЎжңүж ҮйўҳпјҢжҳҜеӣ дёәе®ғдёҚжҳҜжҠ“еҸ–еҫ—з»“жһңпјҢиҖҢжҳҜGoogle еҹәдәҺanchor text еҶіе®ҡиҝҷдёӘз»“жһңжҳҜжҹҘиҜўжүҖжңҹжңӣеҫ—еҲ°зҡ„еҘҪз»“жһңгҖӮеҗҢж ·зҡ„пјҢ第15еҸ·з»“жһңжҳҜдёҖдёӘз”өеӯҗйӮ®д»¶ең°еқҖпјҢеҪ“然иҝҷд№ҹжҳҜеҹәдәҺanchor textзҡ„з»“жһңпјҢиҖҢйқһеҸҜжҠ“еҸ–еҫ—з»“жһңгҖӮ
жүҖжңүз»“жһңйғҪжҳҜеҗҲзҗҶзҡ„й«ҳиҙЁйҮҸйЎөйқўпјҢиҖҢдё”жңҖеҗҺжЈҖжҹҘпјҢжІЎжңүеқҸиҝһжҺҘгҖӮиҝҷдё»иҰҒеҪ’еҠҹдәҺ他们жңүеҫҲй«ҳзҡ„PageRankгҖӮPageRankзҡ„зҷҫеҲҶжҜ”дҪҝз”ЁзәўиүІжқЎеҪўеӣҫиЎЁзӨәгҖӮжңҖеҗҺпјҢиҝҷйҮҢзҡ„з»“жһңдёӯпјҢжІЎжңүеҸӘжңүBillжІЎжңүClinton жҲ–еҸӘжңү Clinton жІЎжңүBill зҡ„пјҢиҝҷжҳҜеӣ дёәжҲ‘们еңЁе…ій”®иҜҚеҮәзҺ°ж—¶дҪҝз”ЁдәҶйқһеёёйҮҚиҰҒзҡ„proximityгҖӮеҪ“然еҜ№дёҖдёӘе®һйҷ…зҡ„еҜ№жҗңзҙўеј•ж“Һзҡ„иҙЁйҮҸжөӢиҜ•еә”иҜҘеҢ…жӢ¬е№ҝжіӣзҡ„еҜ№з”ЁжҲ·з ”究жҲ–иҖ…еҜ№жҗңзҙўз»“жһңзҡ„еҲҶжһҗпјҢдҪҶжҳҜжҲ‘们没жңүж—¶й—ҙеҒҡд»ҘдёҠжһҗгҖӮдҪҶжҳҜжҲ‘们йӮҖиҜ·иҜ»иҖ…еңЁ http://google.stanford.edu/flp иҮӘе·ұжөӢиҜ•GoogleгҖӮ
5.1 еӯҳеӮЁйңҖжұӮ
йҷӨжҗңзҙўиҙЁйҮҸеӨ–пјҢGooogleиў«и®ҫи®ЎдёәиғҪеӨҹж¶ҲеҢ–дә’иҒ”зҪ‘规模дёҚж–ӯеўһй•ҝеёҰжқҘзҡ„ж•ҲиғҪй—®йўҳгҖӮдёҖж–№йқўпјҢдҪҝз”Ёй«ҳж•ҲеӯҳеӮЁгҖӮиЎЁдёҖжҳҜеҜ№Googleзҡ„з»ҹи®ЎдёҺеӯҳеӮЁйңҖжұӮзҡ„иҜҰз»ҶеҲҶзұ»пјҢз”ұдәҺеҺӢзј©еҗҺзҡ„еӯҳеӮЁдҪ“з§Ҝдёә53GBпјҢдёәжәҗж•°жҚ®зҡ„дёүеҲҶд№ӢдёҖеӨҡдёҖзӮ№гҖӮе°ұеҪ“еүҚзҡ„зЎ¬зӣҳд»·ж јжқҘиҜҙеҸҜд»Ҙдёәжңүз”Ёиө„жәҗжҸҗдҫӣе»үд»·зҡ„зӣёе…іеӯҳеӮЁи®ҫеӨҮгҖӮжӣҙйҮҚиҰҒзҡ„жҳҜпјҢжҗңзҙўеј•ж“ҺдҪҝз”Ёзҡ„жүҖжңүж•°жҚ®зҡ„жҖ»еҗҲйңҖиҰҒзӣёеә”зҡ„еӯҳеӮЁеӨ§зәҰдёә55GBгҖӮжӯӨеӨ–пјҢеӨ§еӨҡж•°жҹҘиҜўиғҪиў«иҰҒжұӮе……еҲҶдҪҝз”ЁзҹӯеҸҚеҗ‘зҙўеј• [short inverted index]пјҢеңЁжӣҙеҘҪзҡ„зј–з ҒдёҺеҺӢзј©ж–ҮжЎЈзҙўеј•еҗҺпјҢдёҖдёӘй«ҳиҙЁйҮҸзҡ„зҪ‘з»ңжҗңзҙўеј•ж“ҺеҸҜиғҪеҸӘйңҖиҰҒдёҖеҸ°жңү7GBеӯҳеӮЁз©әй—ҙзҡ„ж–°з”өи„‘гҖӮ
5.2 зі»з»ҹжҖ§иғҪ
иҝҷеҜ№жҗңзҙўеј•ж“Һзҡ„жҠ“еҸ–дёҺзҙўеј•жқҘиҜҙеҫҲйҮҚиҰҒгҖӮиҝҷж ·дҝЎжҒҜиў«иҪ¬еҢ–дёәж•°жҚ®зҡ„йҖҹеәҰд»ҘеҸҠзі»з»ҹдё»иҰҒйғЁеҲҶж”№еҸҳеҗҺиў«жөӢиҜ•зҡ„йҖҹеәҰйғҪзӣёеҜ№жӣҙеҝ«гҖӮе°ұGoogleжқҘиҜҙпјҢдё»иҰҒж“ҚдҪңеҢ…жӢ¬пјҡжҠ“еҸ–пјҢзҙўеј•е’ҢжҺ’еәҸгҖӮдёҖж—ҰзЎ¬зӣҳиў«еЎ«ж»ЎгҖҒжҲ–е‘ҪеҗҚжңҚеҠЎеҷЁеҙ©жәғпјҢжҲ–иҖ…е…¶е®ғй—®йўҳеҜјиҮҙзі»з»ҹеҒңжӯўпјҢйғҪеҫҲйҡҫеәҰйҮҸжҠ“еҸ–жүҖйңҖиҰҒеҢ–иҙ№зҡ„ж—¶й—ҙгҖӮе…ЁйғЁиҠұиҙ№еңЁдёӢиҪҪ2еҚғ6зҷҫдёҮдёӘйЎөйқў[еҢ…жӢ¬й”ҷиҜҜйЎөйқў]зҡ„ж—¶й—ҙеӨ§жҰӮжҳҜ9еӨ©гҖӮдҪҶжҳҜеҰӮжһңзі»з»ҹиҝҗиЎҢжӣҙдёәжөҒз•…пјҢиҝҷдёӘиҝҮзЁӢиҝҳеҸҜд»Ҙжӣҙеҝ«пјҢжңҖеҗҺзҡ„1еҚғ1зҷҫдёӘйЎөйқўеҸӘдҪҝз”ЁдәҶ63дёӘе°Ҹж—¶пјҢе№іеқҮ4зҷҫдёҮжҜҸеӨ©пјҢжҜҸз§’48.5йЎөгҖӮзҙўеј•зҡ„иҝҗиЎҢйҖҹеәҰеҝ«дәҺжҠ“еҸ–йҖҹеәҰзҡ„йҮҚиҰҒеҺҹеӣ жҳҜжҲ‘们иҠұиҙ№дәҶи¶іеӨҹзҡ„ж—¶й—ҙжқҘдјҳеҢ–зҙўеј•зЁӢеәҸпјҢдҪҝе®ғдёҚиҰҒжҲҗдёә瓶йўҲгҖӮдјҳеҢ–еҢ…жӢ¬еҜ№жң¬ең°зЎ¬зӣҳдёҠзҡ„ж–ҮжЎЈзҡ„зҙўеј•иҝӣиЎҢеӨ§и§„жЁЎзҡ„еҚҮзә§е’ҢжӣҝжҚўе…ій”®зҡ„ж•°жҚ®з»“жһ„гҖӮзҙўеј•зҡ„йҖҹеәҰиҫҫеҲ°еӨ§жҰӮ54йЎөжҜҸз§’гҖӮжҺ’еәҸеҸҜд»Ҙе®Ңе…Ёе№іиЎҢдҪңдёҡпјҢдҪҝз”ЁеӣӣеҸ°жңәеҷЁпјҢж•ҙдёӘеӨ„зҗҶж—¶й—ҙиҠұиҙ№иҝ‘24дёӘе°Ҹж—¶гҖӮ
5.3 жҗңзҙўжҖ§иғҪ
жҸҗй«ҳжҗңзҙўжҖ§иғҪ并дёҚжҳҜжң¬ж¬ЎжҲ‘д»¬з ”з©¶зҡ„йҮҚзӮ№гҖӮеҪ“еүҚзүҲжң¬зҡ„Googleиҝ”еӣһеӨҡж•°жҹҘиҜўз»“жһңзҡ„ж—¶й—ҙжҳҜ1еҲ°10з§’гҖӮиҝҷдёӘж—¶й—ҙдё»иҰҒеҸ—еҲ°зЎ¬зӣҳIOд»ҘеҸҠNFS[зҪ‘з»ңж–Ү件系з»ҹпјҢеҪ“зЎ¬зӣҳе®үзҪ®еҲ°и®ёеӨҡжңәеҷЁдёҠж—¶дҪҝз”Ё] зҡ„йҷҗеҲ¶гҖӮиҝӣдёҖжӯҘиҜҙпјҢGoogleжІЎжңүеҒҡд»»дҪ•дјҳеҢ–пјҢдҫӢеҰӮжҹҘиҜўзј“еҶІеҢәпјҢеёёз”ЁиҜҚжұҮеӯҗзҙўеј•пјҢе’Ңе…¶е®ғеёёз”Ёзҡ„дјҳеҢ–жҠҖжңҜгҖӮжҲ‘们еҖҫеҗ‘дәҺйҖҡиҝҮеҲҶеёғејҸпјҢ硬件пјҢиҪҜ件пјҢе’Ңз®—жі•зҡ„ж”№иҝӣжқҘжҸҗй«ҳGoogleзҡ„йҖҹеәҰгҖӮжҲ‘们зҡ„зӣ®ж ҮжҳҜжҜҸз§’иғҪеӨ„зҗҶеҮ зҷҫдёӘиҜ·жұӮгҖӮиЎЁ2жңүеҮ дёӘзҺ°еңЁзүҲжң¬Googleе“Қеә”жҹҘиҜўж—¶й—ҙзҡ„дҫӢеӯҗгҖӮе®ғ们иҜҙжҳҺIOзј“еҶІеҢәеҜ№еҶҚж¬ЎжҗңзҙўйҖҹеәҰзҡ„еҪұе“ҚгҖӮ
еҸҰеӨ–дёҖзҜҮеҸӮиҖғиҜ‘ж–Үпјҡhttp://blog.csdn.net/fxy_2002/archive/2004/12/23/226604.aspx
еҺҹдҪңиҖ…: Sergey Brin and Lawrence PageиҜ‘иҖ…: йӣ·еЈ°еӨ§йӣЁзӮ№еӨ§ (Blog)
иҜ‘иҖ…пјҡжң¬ж–ҮжҳҜи°·жӯҢеҲӣе§ӢдәәSergeyе’ҢLarryеңЁж–ҜеқҰзҰҸеӨ§еӯҰи®Ўз®—жңәзі»иҜ»еҚҡеЈ«ж—¶зҡ„дёҖзҜҮи®әж–ҮгҖӮеҸ‘иЎЁдәҺ1997е№ҙгҖӮGoogleзҡ„дёҖеҲҮеә”иҜҘйғҪиө·жәҗдёҺжӯӨгҖӮж·ұе…ҘдәҶи§ЈGoogleпјҢж·ұе…ҘдәҶи§Јдә’иҒ”зҪ‘зҡ„жңӘжқҘпјҢеҪ“иҜ»жӯӨж–ҮгҖӮжҲ‘жҠҠе…Ёж–ҮеҲҶжҲҗ6дёӘйғЁеҲҶпјҢжҺЁиҚҗеҲ°иҝҷйҮҢгҖӮжңүе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘдёҖиө·жқҘзҝ»иҜ‘гҖӮ
жҲ‘жІЎжңүеҸ‘зҺ°жң¬ж–Үзҡ„е®Ңж•ҙдёӯиҜ‘пјҢеҸӘжүҫеҲ°дәҶиҝҷдёӘзүҮж®өпјҢз”ұxfygxжңӢеҸӢзҝ»иҜ‘дәҶжң¬ж–Үзҡ„第дёҖйғЁеҲҶпјҢе…¶д»–дјјд№ҺжІЎжңүе…ЁйғЁе®ҢжҲҗгҖӮ
жүҖд»ҘпјҢиҝҷйғЁеҲҶиҜ‘ж–ҮжҳҜxfygxеҺҹдҪңпјҢиҖҢйқһжҲ‘зҡ„зҝ»иҜ‘пјҒжҲ‘еҸӘжҳҜе°ұиҮӘе·ұзҡ„зҗҶи§ЈеҒҡдәҶдәӣж”№еҠЁгҖӮеҰӮжһңжңүе№ёxfygxжңӢеҸӢиғҪзңӢеҲ°жҲ‘еңЁд»–/еҘ№еҚҡе®ўзҡ„з•ҷиЁҖпјҢжқҘжҲ‘们иҜ‘иЁҖпјҢжҲ‘йқһеёёеёҢжңӣиғҪжҠҠжң¬ж–ҮиҪ¬еҲ°д»–/еҘ№еҗҚдёӢгҖӮ
еҸҰеӨ–пјҢеҰӮжһңжӮЁеҸ‘зҺ°е·Іжңүе…¶д»–еҮәиүІзҡ„е®Ңж•ҙдёӯиҜ‘зүҲдәҶпјҢиҜ·е‘ҠиҜүжҲ‘们гҖӮе…Қеҫ—иҜ‘иҖ…们йҮҚеӨҚеҠіеҠЁгҖӮ
ж‘ҳиҰҒ
еңЁжң¬ж–ҮдёӯпјҢжҲ‘们е°Ҷд»Ӣз»ҚGoogleпјҢдёҖдёӘе……еҲҶеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件пјҲиҜ‘иҖ…пјҡеҚіHTMLж–Ү件пјүз»“жһ„иҝӣиЎҢжҗңзҙўзҡ„еӨ§и§„жЁЎжҗңзҙўеј•ж“Һзҡ„еҺҹеһӢгҖӮGoogleеҸҜд»Ҙжңүж•Ҳең°еҜ№дә’иҒ”зҪ‘пјҲWebпјүиө„жәҗиҝӣиЎҢзҲ¬иЎҢжҗңзҙўпјҲcrawlпјүгҖ”жіЁ 1гҖ•е’Ңзҙўеј•пјҢжҜ”зӣ®еүҚе·Із»ҸеӯҳеңЁзҡ„зі»з»ҹжңүжӣҙд»Өдәәж»Ўж„Ҹзҡ„жҗңзҙўз»“жһңгҖӮиҜҘеҺҹеһӢзҡ„ж•°жҚ®еә“еҢ…жӢ¬2400дёҮйЎөйқўзҡ„е…Ёж–Үе’Ңд№Ӣй—ҙзҡ„й“ҫжҺҘпјҢеҸҜйҖҡиҝҮhttp://google.stanford.edu/и®ҝй—®гҖӮ
и®ҫи®Ўжҗңзҙўеј•ж“ҺжҳҜдёҖйЎ№еҜҢжңүжҢ‘жҲҳзҡ„д»»еҠЎгҖӮжҗңзҙўеј•ж“Һдёәж•°д»Ҙдәҝи®Ўзҡ„зҪ‘йЎөе»әз«Ӣзҙўеј•пјҢиҖҢиҝҷдәӣзҪ‘йЎөеҢ…еҗ«дәҶеҗҢж ·ж•°йҮҸзә§зҡ„дёҚеҗҢиҜҚиҜӯгҖӮжҜҸеӨ©е“Қеә”ж•°еҚғдёҮи®Ўзҡ„жҹҘиҜўиҜ·жұӮгҖӮе°Ҫз®ЎеӨ§и§„жЁЎзҪ‘з»ңжҗңзҙўеј•ж“ҺжҳҜеҫҲйҮҚиҰҒзҡ„пјҢдҪҶеңЁиҝҷдёӘйўҶеҹҹеҫҲе°‘жңүзҗҶи®әз ”з©¶гҖӮжӣҙз”ұдәҺжҠҖжңҜзҡ„йЈһйҖҹеҸ‘еұ•е’Ңдә’иҒ”зҪ‘зҡ„жҷ®еҸҠпјҢд»ҠеӨ©иҝҷж ·зҡ„жҗңзҙўеј•ж“Һе’Ңдёүе№ҙеүҚзҡ„жҗңзҙўеј•ж“ҺдјҡжҳҜйқһеёёдёҚеҗҢзҡ„гҖӮжң¬ж–ҮеҜ№жҲ‘们зҡ„еӨ§и§„жЁЎжҗңзҙўеј•ж“ҺиҝӣиЎҢдәҶж·ұе…Ҙзҡ„и®Ёи®әпјҢиҝҷд№ҹжҳҜзӣ®еүҚдёәжӯўжҲ‘们жүҖзҹҘйҒ“зҡ„е…¬ејҖеҸ‘иЎЁзҡ„第дёҖзҜҮеҰӮжӯӨиҜҰз»Ҷзҡ„и®Ёи®әгҖӮ
йҷӨдәҶеҰӮдҪ•жҠҠдј з»ҹзҡ„жҗңзҙўжҠҖжңҜжү©еұ•еҲ°еүҚжүҖжңӘжңүзҡ„жө·йҮҸж•°жҚ®пјҢжҲ‘们иҝҳйқўдёҙиҝҷж ·дёҖдёӘж–°зҡ„жҠҖжңҜжҢ‘жҲҳпјҡеҰӮдҪ•дҪҝз”Ёи¶…ж–Үжң¬ж–Ү件жүҖи•ҙеҗ«зҡ„жү©еұ•дҝЎжҒҜд»Ҙдә§з”ҹжӣҙеҘҪзҡ„жҗңзҙўз»“жһңгҖӮжң¬ж–Үи®Ёи®әдәҶеҰӮдҪ•е»әз«ӢдёҖдёӘе®һз”Ёзҡ„еӨ§и§„жЁЎзі»з»ҹпјҢд»ҘеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件дёӯзҡ„йўқеӨ–дҝЎжҒҜгҖӮеҸҰеӨ–пјҢжҲ‘们д№ҹе…іжіЁдәҶеҰӮдҪ•жңүж•ҲеӨ„зҗҶи¶…ж–Үжң¬ж–Ү件дёҚеҸҜжҺ§зҡ„й—®йўҳпјҢеӣ дёәдәә们еҸҜд»ҘйҡҸж„ҸеҸ‘иЎЁи¶…ж–Ү жң¬ж–Ү件пјҲиҜ‘иҖ…пјҡеҰӮдёӘдәәзҪ‘йЎөпјүгҖӮ
е…ій”®иҜҚ
World Wide Web, Search Engines, Information retrieval, PageRank, Google
1.з®Җд»Ӣ
дә’иҒ”зҪ‘еҜ№дҝЎжҒҜжЈҖзҙўпјҲInformation RetrievalпјүйўҶеҹҹдә§з”ҹдәҶж–°зҡ„жҢ‘жҲҳгҖӮзҪ‘дёҠзҡ„дҝЎжҒҜж•°йҮҸжҳҜеңЁдёҚж–ӯзҡ„еҝ«йҖҹеўһй•ҝпјҢеҗҢж—¶жңүи¶ҠжқҘи¶ҠеӨҡеҜ№зҪ‘з»ңжҗңзҙўжҜ«ж— з»ҸйӘҢзҡ„ж–°з”ЁжҲ·дёҠзҪ‘гҖӮеңЁзҪ‘дёҠеҶІжөӘж—¶пјҢдәә们дёҖиҲ¬дјҡеҲ©з”ЁзҪ‘з»ңзҡ„вҖңй“ҫжҺҘеӣҫвҖқпјҲиҜ‘иҖ…пјҡжғіеғҸжҜҸдёӘзҪ‘йЎөжҳҜдёҖдёӘзӮ№пјҢзҪ‘йЎөд№Ӣй—ҙзҡ„й“ҫжҺҘжҳҜд»ҺдёҖдёӘзӮ№жҢҮеҗ‘еҸҰдёҖдёӘзӮ№зҡ„иҫ№пјҢиҝҷе°ұжһ„жҲҗдәҶдёҖеј жңүеҗ‘еӣҫгҖӮпјүгҖӮиҖҢиҝҷз»Ҹеёёд»ҺдёҖдёӘдәәе·Ҙз»ҙжҠӨзҡ„зҪ‘еқҖеҲ—иЎЁпјҲеҰӮYahoo!пјүжҲ–жҳҜдёҖдёӘжҗңзҙўеј•ж“ҺејҖе§ӢгҖӮдәәе·Ҙз»ҙжҠӨзҡ„еҲ—иЎЁжңүж•ҲиҰҶзӣ–дәҶжөҒиЎҢзҡ„дё»йўҳпјҢдҪҶиҝҷдәӣжҳҜдё»и§Ӯзҡ„пјҢиҠұиҙ№й«ҳжҳӮпјҢжӣҙж–°зј“ж…ўпјҢ并且дёҚиғҪиҰҶзӣ–е…ЁйғЁзҡ„дё»йўҳпјҢзү№еҲ«жҳҜеҶ·еғ»зҡ„дё»йўҳгҖӮдҫқиө–е…ій”®иҜҚеҢ№й…Қзҡ„иҮӘеҠЁжҗңзҙўеј•ж“ҺйҖҡеёёиҝ”еӣһеӨӘеӨҡзҡ„дҪҺиҙЁйҮҸзҡ„еҢ№й…Қз»“жһңгҖӮжӣҙзіҹзҡ„жҳҜпјҢдёҖдәӣе№ҝе‘Ҡе•ҶйҖҡиҝҮжҹҗдәӣж–№ејҸиҜҜеҜјжҗңзҙўеј•ж“Һд»ҘиҜ•еӣҫеҗёеј•дәә们зҡ„жіЁж„ҸеҠӣгҖӮжҲ‘们е»әз«ӢдәҶдёҖдёӘеӨ§и§„жЁЎжҗңзҙўеј•ж“ҺжқҘи§ЈеҶіе·ІеӯҳеңЁзі»з»ҹзҡ„и®ёеӨҡй—®йўҳгҖӮе®ғе……еҲҶеҲ©з”Ёи¶…ж–Үжң¬ж–Ү件жүҖиЎЁиҫҫйўқеӨ–дҝЎжҒҜжқҘжҸҗдҫӣжӣҙй«ҳиҙЁйҮҸзҡ„жҗңзҙўз»“жһңгҖӮжҲ‘们йҖүжӢ©иҝҷдёӘеҗҚеӯ—пјҢGoogleпјҢжҳҜеӣ дёәе®ғжҳҜgoogolпјҲиЎЁзӨә10зҡ„100ж¬Ўж–№)иҝҷдёӘиҜҚзҡ„еёёз”ЁжӢјеҶҷжі•гҖӮиҖҢиҝҷдёӘиҜҚзҡ„ж„Ҹд№үдёҺжҲ‘们е»әз«ӢиҝҷдёӘеӨ§и§„жЁЎжҗңзҙўеј•ж“Һзҡ„зӣ®ж ҮжҳҜйқһеёёдёҖиҮҙзҡ„гҖӮ
1.1 дә’иҒ”зҪ‘жҗңзҙўеј•ж“Һ -- жү©еұ•пјҡ1994 - 2000
жҗңзҙўеј•ж“ҺжҠҖжңҜеҝ…йЎ»жһҒеӨ§и§„жЁЎең°жү©еұ•жүҚиғҪиө¶дёҠдә’иҒ”зҪ‘зҡ„еҸ‘еұ•жӯҘдјҗгҖӮеңЁ1994е№ҙ,жңҖж—©зҡ„ webжҗңзҙўеј•ж“Һд№ӢдёҖпјҢWorld Wide Web Worm(WWWW) [McBryan 94]е·Із»Ҹзҙўеј•дәҶ11дёҮwebйЎөйқўе’Ңж–ҮжЎЈгҖӮеҲ°дәҶ1997е№ҙзҡ„11жңҲпјҢйЎ¶зә§зҡ„жҗңзҙўеј•ж“ҺеЈ°з§°зҡ„зҙўеј•зҡ„йЎөйқўж•°йҮҸд»Һ2зҷҫдёҮ(WebCrawler) еҲ°10дәҝ(ж №жҚ® Search Engine Watch)гҖӮеҸҜд»ҘжғіеғҸеҲ°2000е№ҙпјҢзҙўеј•е…ЁйғЁзҡ„Webе°ҶйңҖиҰҒеҢ…еҗ«и¶…иҝҮеҚҒдәҝзҡ„ж–ҮжЎЈгҖӮеҗҢж—¶пјҢжҗңзҙўеј•ж“ҺйңҖиҰҒеӨ„зҗҶзҡ„жҹҘиҜўиҜ·жұӮд№ҹдјҡжңүдёҚеҸҜжғіеғҸзҡ„еўһй•ҝгҖӮеңЁ1994е№ҙ 3жңҲеҲ°4жңҲй—ҙпјҢWorld Wide Web Wormе№іеқҮжҜҸеӨ©ж”¶еҲ°1500дёӘжҹҘиҜўгҖӮиҖҢеҲ°дәҶ1997е№ҙзҡ„11жңҲпјҢAltavistaеЈ°з§°гҖҖе®ғе№іеқҮжҜҸеӨ©иҰҒеӨ„зҗҶеӨ§зәҰ2еҚғдёҮзҡ„жҹҘиҜўгҖӮйҡҸзқҖwebзҡ„з”ЁжҲ·е’ҢдҪҝз”Ёжҗңзҙўеј•ж“Һзҡ„иҮӘеҠЁзі»з»ҹж•°йҮҸзҡ„еўһеҠ пјҢеҲ°2000е№ҙпјҢйЎ¶зә§зҡ„жҗңзҙўеј•ж“ҺжҜҸеӨ©е°ҶдјҡйңҖиҰҒеӨ„зҗҶж•°д»Ҙдәҝи®Ўзҡ„жҹҘиҜўгҖӮжҲ‘们зҡ„зі»з»ҹзҡ„зӣ®ж ҮжҳҜи§ЈеҶіиҝҷдәӣз”ұжҗңзҙўеј•ж“ҺеӨ§и§„жЁЎжү©еұ•жүҖеёҰжқҘзҡ„й—®йўҳпјҢеҢ…жӢ¬иҙЁйҮҸе’ҢеҸҜжү©еұ•жҖ§гҖӮ
1.2 Google:дёҺWebеҗҢжӯҘеҸ‘еұ•
еҚідҫҝе»әз«ӢдёҖдёӘйҖӮеә”д»ҠеӨ©дә’иҒ”зҪ‘дҝЎжҒҜйҮҸзҡ„жҗңзҙўеј•ж“Һе·Із»ҸйқўдёҙзқҖи®ёеӨҡзҡ„жҢ‘жҲҳгҖӮжҲ‘们йңҖиҰҒдҪҝз”Ёеҝ«йҖҹзҲ¬иЎҢжҗңзҙўжҠҖжңҜ收йӣҶwebж–Ү档并дҝқжҢҒе®ғ们зҡ„еҸҠж—¶жӣҙж–°пјӣжҲ‘们йңҖиҰҒеҸҜд»Ҙжңүж•ҲеӯҳеӮЁж–ҮжЎЈзҙўеј•е’Ңж–ҮжЎЈиҮӘиә«пјҲиҝҷдёҚжҳҜеҝ…йЎ»зҡ„пјүзҡ„жө·йҮҸеӯҳеӮЁз©әй—ҙпјӣжҲ‘们йңҖиҰҒеҸҜд»Ҙжңүж•ҲеӨ„зҗҶж•°зҷҫGBж•°жҚ®зҡ„зҙўеј•зі»з»ҹпјӣжҲ‘们иҝҳйңҖиҰҒеҸҜд»ҘеңЁдёҖз§’еҶ…еӨ„зҗҶжҲҗзҷҫдёҠеҚғзҡ„жҹҘиҜўзҡ„и®Ўз®—иғҪеҠӣгҖӮ
иҝҷдәӣд»»еҠЎйғҪйҡҸзқҖWebзҡ„еўһй•ҝиҖҢж„ҲеҸ‘еҸҳзҡ„еӣ°йҡҫгҖӮ然иҖҢпјҢ硬件жҖ§иғҪзҡ„жҸҗй«ҳе’Ңиҙ№з”Ёзҡ„йҷҚдҪҺеҸҜд»ҘйғЁеҲҶзҡ„жҠөж¶Ҳиҝҷдәӣеӣ°йҡҫгҖӮдҪҶжҹҗдәӣж–№йқўжҳҜдёӘдҫӢеӨ–пјҢеҰӮзЎ¬зӣҳж•°жҚ®иҜ»еҸ–зҡ„йҖҹеәҰе’Ңж“ҚдҪңзі»з»ҹзҡ„йІҒжЈ’жҖ§пјҲиҜ‘иҖ…пјҡеҸҜд»ҘйҖҡдҝ—ең°зҗҶи§ЈдёәзЁіе®ҡжҖ§пјүйғҪжІЎжңүжҳҫи‘—жҸҗй«ҳгҖӮеңЁи®ҫи®ЎGoogleзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们已з»ҸиҖғиҷ‘еҲ°дәҶWeb е’ҢжҠҖжңҜиҝҷдёӨж–№йқўзҡ„еҸ‘еұ•гҖӮGoogleиў«и®ҫи®ЎдёәеҸҜд»ҘйҖӮеә”жһҒеӨ§ж•°жҚ®йҮҸгҖӮе®ғжңүж•ҲдҪҝз”ЁеӯҳеӮЁз©әй—ҙжқҘдҝқеӯҳзҙўеј•гҖӮе®ғзҡ„ж•°жҚ®з»“жһ„иў«дјҳеҢ–д»ҘдҫҝеҸҜд»Ҙеҝ«йҖҹе’Ңжңүж•Ҳзҡ„еӯҳеҸ–ж•°жҚ®пјҲи§Ғ 4.2иҠӮ)гҖӮеҸҰеӨ–пјҢжҲ‘们и®ӨдёәпјҢзӣёеҜ№дәҺж–Үжң¬д»ҘеҸҠHTMLж–ҮжЎЈж•°йҮҸзҡ„еўһй•ҝпјҢзҙўеј•е’ҢеӯҳеӮЁиҠұиҙ№е®ғ们зҡ„иҙ№з”ЁжңҖз»ҲдјҡдёӢйҷҚ(и§Ғйҷ„еҪ•B)гҖӮеӣ жӯӨпјҢGoogleиҝҷж ·зҡ„йӣҶдёӯејҸпјҲиҜ‘иҖ…пјҡиҖҢйқһеҲҶеёғеҲ°и®ёеӨҡиҝңзЁӢи®Ўз®—жңәпјҢеҰӮP2Pзі»з»ҹпјүжҗңзҙўзі»з»ҹйҡҸзқҖдә’иҒ”зҪ‘зҡ„еҸ‘еұ•иҖҢжү©е®№е°ұжҲҗдёәеҸҜиғҪгҖӮ
1.3 и®ҫи®Ўзӣ®ж Ү
1.3.1 жҸҗй«ҳжҗңзҙўиҙЁйҮҸ
жҲ‘们зҡ„дё»иҰҒзӣ®ж ҮжҳҜжҸҗй«ҳwebжҗңзҙўеј•ж“Һзҡ„иҙЁйҮҸгҖӮеңЁ1994е№ҙпјҢдёҖдәӣдәәи®Өдёәз”ЁдёҖдёӘе®Ңж•ҙзҡ„жҗңзҙўзҙўеј•е°ұеҸҜд»ҘеҫҲе®№жҳ“ең°жүҫеҲ°д»»дҪ•дҝЎжҒҜгҖӮеңЁ1994е№ҙдә’иҒ”зҪ‘жңҖдҪіпјҚпјҚеҜјиҲӘе‘ҳдёҠпјҢжңүиҝҷж ·зҡ„иҜқ"жңҖеҘҪзҡ„еҜјиҲӘжңҚеҠЎеә”иҜҘжҳҜдҪҝз”ЁжҲ·еҸҜд»ҘеҫҲе®№жҳ“зҡ„еңЁWebдёҠжүҫеҲ°д»»дҪ•дҝЎжҒҜ"гҖӮ然иҖҢпјҢеҲ°1997пјҢиҝҷдёӘд»»еҠЎд»ҚжҳҜйқһеёёеӣ°йҡҫзҡ„гҖӮеңЁжңҖиҝ‘дҪҝз”Ёжҗңзҙўеј•ж“Һзҡ„з”ЁжҲ·йғҪеҸҜд»ҘеҫҲе®№жҳ“зҡ„иҜҒе®һзҙўеј•зҡ„е®Ңж•ҙжҖ§е№¶дёҚжҳҜеҶіе®ҡжҗңзҙўз»“жһңиҙЁйҮҸзҡ„е”ҜдёҖеӣ зҙ гҖӮ"еһғеңҫз»“жһң" з»ҸеёёдјҡдҪҝз”ЁжҲ·жүҫдёҚеҲ°зңҹжӯЈж„ҹе…ҙи¶Јзҡ„з»“жһңгҖӮе®һйҷ…дёҠпјҢеҲ°1997е№ҙзҡ„еҚҒдёҖжңҲпјҢеӣӣдёӘйЎ¶зә§жҗңзҙўеј•ж“ҺдёӯпјҢд»…д»…еҸӘжңүдёҖдёӘеҸҜд»ҘеңЁжҗңзҙўж—¶еҸ‘зҺ°е®ғиҮӘиә«(еҜ№жҹҘиҜўиҮӘе·ұеҗҚеӯ—зҡ„иҜ·жұӮпјҢиҝ”еӣһз»“жһңдёӯе°ҶиҮӘе·ұжҺ’еңЁз»“жһңдёӯзҡ„еүҚеҚҒеҗҚ)гҖӮдә§з”ҹиҝҷдёӘй—®йўҳзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖжҳҜеңЁиҝҷдәӣжҗңзҙўеј•ж“Һзҡ„зҙўеј•еә“дёӯж–ҮжЎЈзҡ„ж•°йҮҸжҲҗж•°йҮҸзә§ең°еўһй•ҝпјҢиҖҢз”ЁжҲ·зңӢиҝҷд№ҲеӨҡж–ҮжЎЈзҡ„иғҪеҠӣеҚҙдёҚеҸҜиғҪиҝҷж ·еўһй•ҝгҖӮз”ЁжҲ·еҫҖеҫҖеҸӘзңӢз»“жһңдёӯзҡ„еүҚж•°еҚҒдёӘгҖӮеӣ жӯӨпјҢйҡҸзқҖж–Ү档规模зҡ„еўһеҠ пјҢжҲ‘们йңҖиҰҒе·Ҙе…·жқҘжҸҗй«ҳжҹҘеҮҶзҺҮпјҲеңЁеүҚеҚҒдёӘз»“жһңдёӯиҝ”еӣһзӣёе…іеҶ…е®№пјүгҖӮе®һйҷ…дёҠпјҢжҲ‘们иҜҙзҡ„"зӣёе…і"жҳҜжҢҮжңҖеҘҪзҡ„йӮЈдёҖд»ҪпјҢеӣ дёәеҸҜиғҪдјҡжңүеҮ дёҮд»ҪвҖңзЁҚеҫ®вҖңзӣёе…ізҡ„ж–ҮжЎЈгҖӮжҹҘеҮҶзҺҮеңЁжҲ‘们зҡ„зңјдёӯжҳҜеҰӮжӯӨзҡ„йҮҚиҰҒпјҢд»ҘиҮідәҺжҲ‘们з”ҡиҮіж„ҝж„ҸдёәжӯӨжҚҹеӨұдёҖдәӣжҹҘе…ЁзҺҮгҖӮжңҖиҝ‘зҡ„з ”з©¶жҳҫзӨәпјҢи¶…ж–Үжң¬ж–Ү件дёӯзҡ„дҝЎжҒҜеҸҜд»ҘжңүеҠ©дәҺжҸҗй«ҳжҗңзҙўе’Ңе…¶д»–еә”з”Ё[Marchiori 97] [Spertus 97] [Weiss 96] [Kleinberg 98]гҖӮзү№еҲ«жҳҜзҪ‘йЎөй“ҫжҺҘзҡ„з»“жһ„пјҢд»ҘеҸҠй“ҫжҺҘжң¬иә«зҡ„ж–Үеӯ—пјҢдёәзӣёе…іжҖ§еҲӨе®ҡе’ҢиҝӣиЎҢиҙЁйҮҸзҡ„зӯӣйҖүжҸҗдҫӣдәҶи®ёеӨҡдҝЎжҒҜгҖӮGoogleдҪҝз”ЁдәҶзҪ‘йЎөй“ҫжҺҘз»“жһ„е’Ңй”ҡпјҲиҜ‘иҖ…пјҡHTMLдёӯзҡ„иҜӯжі•пјҢиЎЁзӨәдёҖдёӘжҢҮеҗ‘зҪ‘йЎөзҡ„й“ҫжҺҘпјүй“ҫжҺҘдёӯзҡ„ж–Үеӯ—гҖӮпјҲиҜҰи§Ғ2.1е’Ң2.2иҠӮпјү
1.3.2 жҗңзҙўеј•ж“Һзҡ„зҗҶи®әз ”з©¶
йҡҸзқҖWEBзҡ„е·ЁеӨ§еҸ‘еұ•пјҢдә’иҒ”зҪ‘д№ҹи¶ҠжқҘи¶Ҡе•ҶдёҡеҢ–гҖӮеңЁ1993е№ҙпјҢеҸӘжңү1.5%зҡ„webжңҚеҠЎеҷЁжҳҜ.comзҡ„еҹҹеҗҚгҖӮиҖҢеҲ°дәҶ1997е№ҙпјҢиҝҷдёӘж•°еӯ—е·Із»ҸеҸҳжҲҗдәҶ60%гҖӮеҗҢж—¶пјҢжҗңзҙўеј•ж“Һзҡ„д»ҺеӯҰжңҜз ”з©¶еҸҳжҲҗдәҶе•ҶдёҡжҖ§иҙЁгҖӮеҲ°зӣ®еүҚдёәжӯўпјҢеӨ§еӨҡж•°зҡ„жҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘йғҪжҳҜз”ұе…¬еҸёжқҘиҝӣиЎҢзҡ„пјҢеҫҲе°‘жңүиҜҰз»Ҷзҡ„жҠҖжңҜиө„ж–ҷиў«е…¬ејҖгҖӮиҝҷеҜјиҮҙдәҶиҝҷйЎ№жҠҖжңҜеёҰжңүдәҶи®ёеӨҡзҘһз§ҳзҡ„иүІеҪ©пјҢ并且жҳҜд»Ҙе№ҝе‘Ҡдёәдё»пјҲи§Ғйҷ„еҪ•AпјүгҖӮеҜ№дәҺGoogleпјҢжҲ‘们жңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„зӣ®ж Үе°ұжҳҜжҺЁеҠЁжҗңзҙўеј•ж“ҺеңЁеӯҰжңҜз•Ңзҡ„еҸ‘еұ•е’ҢзҗҶи§ЈгҖӮ
еҸҰеӨ–зҡ„йҮҚиҰҒзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜе»әз«ӢдёҖдёӘеҸҜд»Ҙи®©дёҖе®ҡж•°йҮҸзҡ„з”ЁжҲ·е®һйҷ…дҪҝз”Ёзҡ„зі»з»ҹгҖӮз”ЁжҲ·дҪҝз”ЁеҜ№жҲ‘们жқҘиҜҙйқһеёёйҮҚиҰҒпјҢеӣ дёәжҲ‘们и®ӨдёәзңҹжӯЈеҲ©з”ЁдәҶзҺ°д»Јдә’иҒ”зҪ‘зі»з»ҹзҡ„жө·йҮҸж•°жҚ®зҡ„з ”з©¶жүҚжҳҜжңҖжңүд»·еҖјзҡ„гҖӮжҜ”еҰӮзҺ°еңЁжҜҸеӨ©жңүж•°еҚғдёҮз”ЁжҲ·жҹҘиҜўпјҢдҪҶз”ұдәҺиҝҷдәӣж•°жҚ®иў«и®Өдёәе…·жңүе•Ҷдёҡд»·еҖјпјҢеҫҲйҡҫжӢҝжқҘдҪңеӯҰжңҜз ”з©¶гҖӮ
жҲ‘们жңҖз»Ҳзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜе»әз«ӢдёҖдёӘеҸҜд»Ҙж”ҜжҢҒеңЁеӨ§и§„жЁЎдә’иҒ”зҪ‘ж•°жҚ®дёҠиҝӣиЎҢз ”з©¶жҙ»еҠЁзҡ„зі»з»ҹжһ„жһ¶гҖӮдёәдәҶж”ҜжҢҒз ”з©¶жҙ»еҠЁпјҢGoogleеӯҳеӮЁдәҶе…ЁйғЁзҡ„еңЁзҲ¬иЎҢжҗңзҙўдёӯеҸ‘зҺ°зҡ„е®һйҷ…ж•°жҚ®пјҢ并еҺӢзј©иө·жқҘгҖӮдё»иҰҒзҡ„зӣ®ж Үд№ӢдёҖжҳҜе»әз«ӢдёҖдёӘзҺҜеўғпјҢеңЁиҝҷдёӘзҺҜеўғдёӯпјҢз ”з©¶иҖ…еҸҜд»ҘеҫҲеҝ«зҡ„еҲ©з”ЁиҝҷдёӘйҡҫеҫ—зҡ„зі»з»ҹпјҢеӨ„зҗҶwebж•°жҚ®пјҢдә§з”ҹд»Өдәәж„ҹе…ҙи¶Јзҡ„з»“жһңгҖӮеңЁзҹӯж—¶й—ҙеҶ…зі»з»ҹе°ұиў«е»әз«Ӣиө·жқҘпјҢе·Із»ҸжңүдёҖдәӣи®әж–ҮдҪҝз”ЁдәҶйҖҡиҝҮGoogleз”ҹжҲҗзҡ„ж•°жҚ®еә“гҖӮиҝҳжңүи®ёеӨҡе…¶е®ғзҡ„йЎ№зӣ®еңЁиҝӣиЎҢд№ӢдёӯгҖӮеҸҰеӨ–зҡ„зӣ®ж ҮжҳҜжҲ‘们еёҢжңӣе»әз«ӢдёҖдёӘзұ»дјјз©әй—ҙз«ҷзҡ„зҺҜеўғпјҢдҪҝеҫ—з ”з©¶иҖ…пјҢз”ҡиҮіжҳҜеӯҰз”ҹеҸҜд»ҘеңЁжҲ‘们зҡ„еӨ§и§„жЁЎwebж•°жҚ®дёҠиҝӣиЎҢе®һйӘҢгҖӮ
гҖ”жіЁ 1гҖ•зҲ¬иЎҢжҗңзҙўпјҢCrawlпјҢжҳҜжҢҮжҗңзҙўеј•ж“Һдјҡи·ҹйҡҸзҪ‘йЎөй—ҙзҡ„й“ҫжҺҘд»ҺдёҖдёӘзҪ‘йЎөвҖңзҲ¬иЎҢвҖқеҲ°дёӢдёҖдёӘзҪ‘йЎөгҖӮиҖҢеҜ№жҜҸдёҖдёӘзҪ‘йЎөзҡ„еҲҶжһҗе’Ңи®°еҪ•пјҢжҲ–иҖ…иҝҷдёӘиҝҮзЁӢзҡ„з»“жһңпјҢеҲҷз§°дёәвҖңзҙўеј•вҖқгҖӮ
2.зі»з»ҹеҠҹиғҪ
Googleжҗңзҙўеј•ж“ҺйҖҡиҝҮдёӨдёӘйҮҚиҰҒеҠҹиғҪжқҘдә§з”ҹй«ҳзІҫзЎ®еәҰзҡ„з»“жһңгҖӮ第дёҖпјҢе®ғеҲ©з”Ёдә’иҒ”зҪ‘зҡ„й“ҫжҺҘз»“жһ„дёәжҜҸдёӘзҪ‘йЎөи®Ўз®—еҮәдёҖдёӘй«ҳиҙЁйҮҸзҡ„жҺ’еҗҚгҖӮиҝҷдёӘжҺ’еҗҚиў«з§°дёәPageRank[жіЁдёҖ]пјҢе…·дҪ“еңЁLarry Page98е№ҙзҡ„и®әж–Ү[Page 98]дёӯжңүиҜҰиҝ°гҖӮ第дәҢпјҢGoogleеҲ©з”Ёй“ҫжҺҘжң¬иә«жқҘжҸҗй«ҳжҗңзҙўз»“жһңзҡ„иҙЁйҮҸгҖӮ
2.1 PageRank: з»ҷдә’иҒ”зҪ‘еёҰжқҘ秩еәҸ
зҺ°жңүзҡ„жҗңзҙўеј•ж“ҺеңЁеҫҲеӨ§зЁӢеәҰдёҠеҝҪз•ҘдәҶдёҖдёӘйҮҚиҰҒиө„жәҗпјҚпјҚжҠҠдә’иҒ”зҪ‘зңӢеҒҡжҳҜдёҖдёӘеј•з”Ёе…ізі»пјҲй“ҫжҺҘе…ізі»пјүеӣҫпјҲи§Ғ第дёҖйғЁеҲҶзҡ„жіЁи§ЈпјүгҖӮжҲ‘们已з»Ҹдә§з”ҹдәҶеҢ…еҗ«5дәҝ1еҚғ8зҷҫдёҮиҝҷж ·зҡ„и¶…ж–Үжң¬й“ҫжҺҘпјҲе°ұжҳҜзҪ‘йЎөжҢҮеҗ‘зҪ‘йЎөзҡ„й“ҫжҺҘпјүзҡ„ең°еӣҫпјҚпјҚиҝҷжҳҜеҜ№ж•ҙдёӘдә’иҒ”зҪ‘зҡ„дёҖдёӘзӣёеҪ“жҳҫи‘—зҡ„йҮҮж ·гҖӮиҝҷж ·зҡ„ең°еӣҫи®©жҲ‘们иғҪеҝ«йҖҹи®Ўз®—зҪ‘йЎөзҡ„вҖңPageRankвҖқпјҚпјҚдёҖдёӘеҜ№дәҺзҪ‘йЎөиў«еј•з”ЁзЁӢеәҰзҡ„е®ўи§ӮиЎЎйҮҸпјҢиҖҢиў«еј•з”ЁзЁӢеәҰдёҺдәә们еҜ№дәҺзҪ‘йЎөйҮҚиҰҒжҖ§зҡ„дё»и§Ӯи®ӨиҜҶд№ҹеҫҲеҘҪең°еҗ»еҗҲгҖӮз”ұдәҺиҝҷж ·зҡ„еҗ»еҗҲпјҢPageRankжҲҗдёәеҜ№з”Ёе…ій”®еӯ—жҗңзҙўзҪ‘йЎөиҝ”еӣһзҡ„з»“жһңиҝӣиЎҢжҺ’еәҸзҡ„жһҒеҘҪж–№ејҸгҖӮеҜ№дәҺжңҖзғӯй—Ёзҡ„еҲҶзұ»пјҢеұҖйҷҗдәҺзҪ‘йЎөж ҮйўҳиҝӣиЎҢз®ҖеҚ•зҡ„ж–Үеӯ—жҹҘжүҫпјҢPageRankжҺ’еәҸеҗҺзҡ„жҗңзҙўз»“жһңж•ҲжһңжһҒеҘҪгҖӮиҖҢеңЁж•ҙдёӘGoogleзі»з»ҹдёӯиҝӣиЎҢе…Ёж–ҮжҹҘжүҫпјҢPageRankзҡ„дҪңз”Ёд№ҹжҳҜйқһеёёжҳҫи‘—зҡ„гҖӮ
2.1.1 PageRank и®Ўз®—з®Җиҝ°
еӯҰжңҜж–ҮзҢ®зҡ„еј•з”ЁжңәеҲ¶иў«еә”з”ЁеҲ°дә’иҒ”зҪ‘дёҠпјҚпјҚдё»иҰҒе°ұжҳҜи®Ўз®—дёҖдёӘзҪ‘йЎөиў«еј•з”ЁпјҢжҲ–иў«еҸҚеҗ‘й“ҫжҺҘзҡ„ж¬Ўж•°гҖӮиҝҷз»ҷеҮәдәҶеҜ№дёҖдёӘзҪ‘йЎөйҮҚиҰҒжҖ§жҲ–иҙЁйҮҸзҡ„дј°и®ЎгҖӮPageRankиҝӣдёҖжӯҘеҸ‘еұ•дәҶиҝҷдёӘжғіжі•пјҡжқҘиҮӘдёҚеҗҢйЎөйқўзҡ„й“ҫжҺҘиў«з»ҷд»ҘдёҚеҗҢзҡ„жқғйҮҚпјҢ并дҫқжҚ®дёҖдёӘзҪ‘йЎөдёҠй“ҫжҺҘзҡ„дёӘж•°жӯЈжҖҒеҢ–гҖӮPageRankзҡ„е®ҡд№үеҰӮдёӢпјҡ
жҲ‘们еҒҮе®ҡзҪ‘йЎөгҖҖAгҖҖжңүиӢҘе№Іе…¶д»–зҪ‘йЎөпјҲT1...TnпјүжҢҮеҗ‘е®ғпјҲеҚіеј•з”Ёе…ізі»пјүгҖӮеҸӮж•°dжҳҜдёҖдёӘ0,1д№Ӣй—ҙзҡ„йҳ»е°јзі»ж•°гҖӮжҲ‘们йҖҡеёёжҠҠdи®ҫдёә0.85гҖӮдёӢдёҖиҠӮдјҡжңүе…ідәҺdзҡ„иҜҰиҝ°гҖӮC(A)жҳҜд»ҺзҪ‘йЎөAжҢҮеҗ‘е…¶д»–зҪ‘йЎөзҡ„й“ҫжҺҘдёӘж•°гҖӮйӮЈд№ҲзҪ‘йЎөAзҡ„PageRankзҡ„и®Ўз®—еҰӮдёӢпјҡ
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
жҲ‘们注ж„ҸеҲ°PageRankжһ„жҲҗдёҖдёӘеҲҶеёғдәҺжүҖжңүзҪ‘йЎөдёҠзҡ„жҰӮзҺҮеҲҶеёғеҮҪж•°пјҢеӣ жӯӨжүҖжңүзҪ‘йЎөзҡ„PageRankжҖ»е’Ңеә”иҜҘдёәгҖҖ1гҖӮ
PageRankпјҢжҲ–PR(A)еҸҜд»ҘйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„еҫӘзҺҜз®—жі•жқҘи®Ўз®—гҖӮиҝҷеҜ№еә”дәҺжӯЈжҖҒеҢ–еҗҺзҡ„дә’иҒ”зҪ‘й“ҫжҺҘзҹ©йҳөзҡ„дё»иҰҒиүҫж №еҗ‘йҮҸзҡ„и®Ўз®—гҖӮеҸҰеӨ–пјҢ2еҚғ6зҷҫдёҮзҪ‘йЎөзҡ„PageRankеҸҜд»ҘеңЁдёҖеҸ°дёӯеһӢжңҚеҠЎеҷЁдёҠпјҢйҖҡиҝҮеҮ е°Ҹж—¶зҡ„и®Ўз®—е®ҢжҲҗгҖӮиҝҷйҮҢжңүеҫҲеӨҡз»ҶиҠӮи¶…еҮәдәҶжң¬и®әж–Үзҡ„и®Ёи®әиҢғеӣҙгҖӮ
2.1.2 зӣҙи§Ӯи§ЈйҮҠ
PageRank еҸҜд»Ҙиў«жғіеғҸжҲҗдёҖдёӘеҜ№з”ЁжҲ·иЎҢдёәе»әз«Ӣзҡ„жЁЎеһӢгҖӮжҲ‘们еҒҮжғідёҖдёӘвҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқпјӣйҡҸжңәең°з»ҷд»–дёҖдёӘзҪ‘йЎөпјӣд»–жј«ж— зӣ®зҡ„ең°зӮ№еҮ»зҪ‘йЎөзҡ„й“ҫжҺҘпјҢиҖҢд»ҺжқҘдёҚзӮ№вҖңиҝ”еӣһй”®вҖқпјӣжңҖз»Ҳд»–и§үеҫ—зғҰдәҶпјҢеҸҲд»ҺеҸҰдёҖдёӘйҡҸжңәзҡ„зҪ‘йЎөд»Һж–°ејҖе§ӢгҖӮеңЁдёҠиҝ°жЁЎеһӢдёӯпјҢвҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқи®ҝй—®дёҖдёӘйЎөйқўзҡ„жҰӮзҺҮе°ұжҳҜиҝҷдёӘйЎөйқўзҡ„PageRankгҖӮиҖҢйҳ»е°јзі»ж•°dпјҢеҲҷжҳҜжҲ‘们зҡ„вҖңйҡҸжңәдёҠзҪ‘иҖ…вҖқеңЁи®ҝй—®дәҶдёҖдёӘйЎөйқўеҗҺпјҢи§үеҫ—зғҰдәҶпјҢејҖе§Ӣи®ҝй—®дёҖдёӘж–°зҡ„йЎөйқўзҡ„жҰӮзҺҮгҖӮдёҠиҝ°жЁЎеһӢзҡ„дёҖдёӘйҮҚиҰҒеҸҳеҪўжҳҜжҠҠйҳ»е°јзі»ж•°dеҠ еҲ°дёҖдёӘзҪ‘йЎөдёҠпјҢиҝҳжҳҜеҠ еҲ°дёҖз»„зҪ‘йЎөдёҠгҖӮиҝҷдёӘеҸҳеҪўдҪҝеҫ—ж•…ж„Ҹж¬әйӘ—зі»з»ҹиҺ·еҫ—й«ҳжҺ’еҗҚзҡ„дјҒеӣҫеҮ д№ҺеҸҳжҲҗдёҚеҸҜиғҪзҡ„гҖӮжҲ‘们еҜ№PageRankжңүиӢҘ干延伸пјҢиҜҰи§ҒиҝҷйҮҢ[Page 98]гҖӮ
еҸҰдёҖдёӘзӣҙи§Ӯзҡ„и§ЈйҮҠжҳҜеҰӮжһңжңүеҫҲеӨҡе…¶д»–зҪ‘йЎөжҢҮеҗ‘дёҖдёӘйЎөйқўпјҢжҲ–иҖ…е…¶д»–жңүеҫҲй«ҳPageRankзҡ„зҪ‘йЎөжҢҮеҗ‘иҝҷдёӘйЎөйқўпјҢиҜҘйЎөйқўеә”иҜҘжңүиҫғй«ҳзҡ„PageRankгҖӮзӣҙи§үе‘ҠиҜүжҲ‘们пјҢеҰӮжһңдёҖдёӘзҪ‘йЎөиў«дә’иҒ”зҪ‘дёҠзҡ„еҫҲеӨҡе…¶д»–зҪ‘йЎөеј•з”ЁпјҢе®ғеә”иҜҘжҳҜеҖјеҫ—е…іжіЁзҡ„гҖӮиҖҢйӮЈдәӣеҸӘжңүдёҖдёӘеј•з”Ёзҡ„йЎөйқўпјҢеҰӮжһңе®ғжқҘиҮӘиұЎYahoo!йҰ–йЎөпјҢйӮЈеӨ§зәҰиҝҷдёӘзҪ‘йЎөд№ҹеҖјеҫ—зңӢзңӢгҖӮеҰӮжһңдёҖдёӘзҪ‘йЎөиҙЁйҮҸдёҚй«ҳжҲ–ж №жң¬е°ұжҳҜдёҖдёӘжӯ»й“ҫжҺҘпјҢYahooйҰ–йЎөеӨҡеҚҠдёҚдјҡй“ҫжҺҘе®ғгҖӮPageRankгҖҖиҖғиҷ‘дәҶдёҠиҝ°дёӨз§Қд»ҘеҸҠд№Ӣй—ҙзҡ„еҗ„з§Қжғ…еҶөпјҢе®ғз”ЁйҖ’еҪ’ж–№ејҸжҠҠзҪ‘йЎөзҡ„жқғйҮҚйҖҡиҝҮдә’иҒ”зҪ‘зҡ„й“ҫжҺҘз»“жһ„дј ж’ӯеҮәеҺ»гҖӮ
2.2 й”ҡй“ҫжҺҘпјҲAnchorпјҢжҳҜHTMLзҡ„иҜӯжі•пјҢеҚізҪ‘йЎөй“ҫжҺҘпјүзҡ„ж–Үжң¬
й“ҫжҺҘзҡ„ж–Үеӯ—еңЁжҲ‘们зҡ„жҗңзҙўеј•ж“ҺдёӯеҸ—еҲ°зү№ж®ҠеӨ„зҗҶгҖӮеӨ§еӨҡж•°жҗңзҙўеј•ж“ҺжҠҠй“ҫжҺҘдёӯзҡ„ж–Үжң¬йғЁеҲҶпјҲжҜ”еҰӮkesoиҝҷдёӘй“ҫжҺҘдёӯзҡ„kesoпјүеҪ’еұһдәҺиҝҷдёӘй“ҫжҺҘжүҖеңЁзҡ„зҪ‘йЎөгҖӮиҖҢжҲ‘们йҷӨжӯӨд№ӢеӨ–пјҢиҝҳжҠҠе®ғеҪ’еұһдәҺиҝҷдёӘй“ҫжҺҘжҢҮеҗ‘зҡ„йЎөйқўгҖӮиҝҷжңүеҮ дёӘеҘҪеӨ„гҖӮ第дёҖпјҢй”ҡй“ҫжҺҘеҜ№иў«жҢҮеҗ‘зҪ‘йЎөзҡ„жҸҸиҝ°пјҢйҖҡеёёжҜ”зҪ‘йЎөжң¬иә«зҡ„жҸҸиҝ°жӣҙеҮҶзЎ®гҖӮ第дәҢпјҢй”ҡй“ҫжҺҘеҸҜиғҪжҢҮеҗ‘йӮЈдәӣдёҚиғҪиў«е»әз«Ӣж–Үжң¬зҙўеј•зҡ„ж–ҮжЎЈпјҢеҰӮеӣҫзүҮгҖҒзЁӢеәҸгҖҒж•°жҚ®еә“гҖӮиҝҷдҪҝеҫ—зҺ°еңЁдёҚиғҪзҲ¬иЎҢжҗңзҙўзҡ„йЎөйқўеҸҜд»Ҙиў«жҗңзҙўеҲ°дәҶгҖӮжіЁж„ҸпјҢд»ҘеүҚд»ҺжңӘиў«зҲ¬иЎҢжҗңзҙўиҝҮзҡ„йЎөйқўеҸҜиғҪдјҡдә§з”ҹй—®йўҳпјҢеӣ дёәе®ғ们зҡ„жңүж•ҲжҖ§д»ҺжңӘиў«йӘҢиҜҒиҝҮгҖӮжҜ”еҰӮжҗңзҙўеј•ж“Һз”ҡиҮідјҡиҝ”еӣһдёҖдёӘжңүй“ҫжҺҘжҢҮеҗ‘пјҢдҪҶе…¶е®һж №жң¬дёҚеӯҳеңЁзҡ„йЎөйқўгҖӮ然иҖҢпјҢз”ұдәҺжҲ‘们еҸҜд»ҘеҜ№з»“жһңжҺ’еәҸпјҢиҝҷдёӘй—®йўҳеҫҲе°‘дјҡеҮәзҺ°гҖӮ
жҠҠй”ҡй“ҫжҺҘдёӯзҡ„ж–Үжң¬дј ж’ӯеҲ°иў«жҢҮеҗ‘зҡ„йЎөйқўиҝҷдёӘжғіжі•пјҢеңЁWorld Wide Web Worm [McBryan 94] е·Із»Ҹиў«е®һж–ҪдәҶгҖӮдё»иҰҒз”ЁдәҺеҜ№йқһж–Үжң¬ж–Ү件зҡ„жҗңзҙўпјҢе’ҢжҠҠжҗңзҙўз»“жһңжү©еұ•еҲ°жӣҙеӨҡдёӢиҪҪж–ҮжЎЈгҖӮиҖҢжҲ‘们дҪҝз”Ёй”ҡй“ҫжҺҘпјҢдё»иҰҒжҳҜеӣ дёәе®ғеҸҜд»ҘжҸҗдҫӣй«ҳиҙЁйҮҸзҡ„з»“жһңгҖӮжңүж•ҲдҪҝз”Ёй”ҡй“ҫжҺҘеңЁжҠҖжңҜдёҠжҳҜеҫҲйҡҫе®һзҺ°зҡ„пјҢеӣ дёәеӨ§йҮҸж•°жҚ®йңҖиҰҒеӨ„зҗҶгҖӮеңЁжҲ‘们зҺ°еңЁзҲ¬иЎҢжҗңзҙўиҝҮзҡ„2еҚғ4зҷҫдёҮзҪ‘йЎөдёӯпјҢжҲ‘们дёә2дәҝ5еҚғ9зҷҫдёҮй”ҡй“ҫжҺҘе»әз«ӢдәҶзҙўеј•гҖӮ
2.3 е…¶д»–еҠҹиғҪ
йҷӨдәҶдҪҝз”ЁPageRankе’ҢеҲ©з”Ёй”ҡй“ҫжҺҘдёӯзҡ„ж–Үжң¬еӨ–пјҢGoogleиҝҳжңүе…¶д»–дёҖдәӣеҠҹиғҪгҖӮ第дёҖпјҢе®ғжңүжүҖжңүзҪ‘йЎөзҡ„дҪҚзҪ®дҝЎжҒҜпјҢеӣ жӯӨеңЁжҗңзҙўиҝҮзЁӢдёӯе……еҲҶеә”з”ЁдәҶжҺҘиҝ‘зЁӢеәҰгҖӮ第дәҢпјҢGoogleгҖҖи®°еҪ•зҪ‘йЎөзҡ„дёҖдәӣи§Ҷи§үиЎЁзҺ°пјҢеҰӮеҚ•иҜҚзҡ„еӯ—дҪ“еӨ§е°ҸгҖӮеӨ§еӯ—дҪ“зҡ„жқғйҮҚжҜ”е°Ҹеӯ—дҪ“иҰҒй«ҳгҖӮ第дёүпјҢе®Ңж•ҙзҡ„еҺҹе§ӢHTMLйЎөйқўиў«дҝқеӯҳдёӢжқҘпјҲеҚіGoogleзҡ„зҪ‘йЎөеҝ«з…§еҠҹиғҪпјүгҖӮ
[жіЁдёҖ]гҖҖPageRankгҖҖеҸҜд»ҘиҜ‘дёәзҪ‘йЎөжҺ’еҗҚпјҢе»әи®®еҗҺйқўе°ұз”ЁеҺҹж–ҮдәҶгҖӮеҸҰеӨ–пјҢPageгҖҖжҒ°жҒ°жҳҜGoogleеҲӣе§Ӣдәәд№ӢдёҖLarry Pageзҡ„姓гҖӮ
3зӣёе…іе·ҘдҪң
еҹәдәҺwebзҡ„жҗңзҙўз ”究жңүдёҖж®өз®Җзҹӯзҡ„зҡ„еҺҶеҸІгҖӮдёҮз»ҙзҪ‘и •иҷ«( wwww )[ mcbryan 94 ]жҳҜ第дёҖдёӘзҪ‘дёҠжҗңзҙўеј•ж“ҺгҖӮдҪҶйҡҸеҗҺ,дә§з”ҹдәҶеҮ дёӘеӯҰйҷўжҙҫзҡ„жҗңзҙўеј•ж“Һ,е…¶дёӯжңүдёҚе°‘зҺ°еңЁе·Із»ҸжҳҜе…¬ејҖзҡ„дёҠеёӮе…¬еҸёдәҶгҖӮзӣёжҜ”Webзҡ„еўһй•ҝе’Ңжҗңзҙўеј•ж“Һзҡ„йҮҚиҰҒжҖ§,зҺ°еңЁеҮ д№ҺжІЎжңүе…ідәҺеҪ“еүҚжҗңзҙўеј•ж“Һжңүд»·еҖјзҡ„з ”з©¶жқҗж–ҷ [Pinkerton 94].гҖӮжҚ®иҝҲе…Ӣе°”.иҢӮдёҒ( lycosе…¬еҸёйҰ–еёӯ科еӯҰ家)[Mauldin] "еҗ„з§ҚжңҚеҠЎ(еҢ…жӢ¬lycos )зҙ§еҜҶзҡ„е®ҲеҚ«зқҖиҝҷдәӣж•°жҚ®еә“" гҖӮ
дёҚиҝҮ,еңЁжҗңзҙўеј•ж“Һзҡ„е…·дҪ“зҡ„зү№зӮ№дёҠе·ІиҝӣиЎҢдәҶзӣёеҪ“зҡ„е·ҘдҪңгҖӮеҜ№зҺ°жңүе•Ҷдёҡжҗңзҙўеј•ж“Һдә§з”ҹзҡ„жҗңзҙўз»“жһңзҡ„еҗҺеӨ„зҗҶе·Із»ҸеҸ–еҫ—дәҶеҚ“жңүжҲҗж•Ҳзҡ„жҲҗжһң,жҲ–жҳҜдә§з”ҹе°Ҹ规模зҡ„вҖңдёӘжҖ§еҢ–зҡ„вҖңжҗңзҙўеј•ж“ҺгҖӮжңҖз»Ҳ,жңүиҝҮдёҚе°‘й’ҲеҜ№дҝЎжҒҜжЈҖзҙўзі»з»ҹзҡ„з ”з©¶,е°Өе…¶жҳҜеҜ№еҸ—жҺ§еҲ¶зҡ„з»“жһңйӣҶзҡ„з ”з©¶гҖӮеңЁйҡҸеҗҺдёӨиҠӮдёӯ,жҲ‘们е°Ҷи®Ёи®әдёҖдәӣеҝ…йЎ»жү©еӨ§з ”究зҡ„йўҶеҹҹ,д»ҘдҫҝжӣҙеҘҪең°еңЁWebдёҠе·ҘдҪңгҖӮ
3.1дҝЎжҒҜжЈҖзҙў
дҝЎжҒҜжЈҖзҙўзі»з»ҹзҡ„з ”з©¶,е·Із»ҸжңүеҫҲеӨҡе№ҙдәҶ,并且жҲҗжһңжҳҫи‘—[Witten 94] гҖӮ 然иҖҢ,еӨ§еӨҡж•°дҝЎжҒҜжЈҖзҙўзі»з»ҹ зҡ„ з ”з©¶ й’ҲеҜ№зҡ„жҳҜ еҸ—жҺ§еҲ¶зҡ„еҗҢиҙЁйӣҶеҗҲ пјҢдҫӢеҰӮ,дё»йўҳзӣёе…ізҡ„科еӯҰи®әж–ҮжҲ–ж–°й—»ж•…дәӢгҖӮзҡ„зЎ®,дҝЎжҒҜжЈҖзҙўзҡ„дё»иҰҒзҡ„еҹәеҮҶ,ж–Үжң¬жЈҖзҙўдјҡи®®[TREC 96] ,з”ЁдәҶдёҖдёӘзӣёеҪ“е°Ҹзҡ„пјҢ并且еҸ—жҺ§еҲ¶зҡ„йӣҶеҗҲ дҪңдёәе…¶еҹәеҮҶгҖӮвҖңйқһеёёеӨ§зҡ„иҜӯж–ҷеә“вҖң; еҹәеҮҶеҸӘжңү20gb еӨ§е°ҸпјҢ зӣёиҫғдәҺжҲ‘们жҗңзҙўиҝҮзҡ„ 2еҚғ4зҷҫдёҮзҪ‘йЎөпјҢжңү147gb зҡ„ж•°жҚ®йҮҸ гҖӮеңЁTREC дёҠе·ҘдҪңеҫҲеҘҪзҡ„жҗңзҙўеј•ж“ҺпјҢжӢҝеҲ°WebдёҠжқҘеҫҖеҫҖж•ҲжһңдёҚдҪігҖӮдёҫдҫӢжқҘиҜҙ,ж ҮеҮҶеҗ‘йҮҸз©әй—ҙжЁЎеһӢиҜ•еӣҫиҝ”еӣһе’ҢжҗңзҙўжқЎд»¶жңҖдёәиҝ‘дјјзҡ„ж–Ү件,еҒҮе®ҡжҗңзҙўе’Ңж–Ү件йғҪжҳҜеҗ„иҮӘж–Үеӯ—е®ҡд№үзҡ„еҗ‘йҮҸгҖӮеҜ№Web иҖҢиЁҖ,иҝҷз§Қзӯ–з•ҘеҸӘдјҡиҝ”еӣһйқһеёёз®Җзҹӯзҡ„ж–Ү件пјҢеҢ…еҗ«жҹҘиҜўжң¬иә«е’ҢеҮ еҸҘиҜқгҖӮдёҫдҫӢжқҘиҜҙ,жҲ‘们已з»ҸзңӢеҲ°дәҶдёҖдёӘдё»иҰҒзҡ„жҗңзҙўеј•ж“Һиҝ”еӣһзҡ„дёҖдёӘйЎөйқўд»…д»…еҗ«жңүвҖңжҜ”е°”.е…Ӣжһ—йЎҝзңҹзіҹвҖң;е’Ңд»ҺвҖңжҜ”е°”.е…Ӣжһ—йЎҝвҖңжҗңзҙўжқҘзҡ„еӣҫзүҮгҖӮ жңүдәәдәүи®әеҲ° ,еңЁWebдёҠз”ЁжҲ·еә”иҜҘжӣҙе…·дҪ“,жӣҙеҮҶзЎ®ең°жҢҮеҮә他们иҰҒд»Җд№Ҳ,并且еңЁжҗңзҙўжҹҘиҜўдёӯеўһж·»жӣҙеӨҡиҜҚгҖӮжҲ‘们еқҡеҶіеҸҚеҜ№иҝҷз§Қз«ӢеңәгҖӮеҰӮжһңз”ЁжҲ·еҸ‘еҮәеҜ№вҖңжҜ”е°”е…Ӣжһ—йЎҝвҖңзҡ„жҗңзҙўжҹҘиҜў ,他们еә”еҫ—еҲ°еҗҲзҗҶзҡ„з»“жһң,еӣ дёәе°ұиҝҷдёӘиҜқйўҳеӯҳеңЁзқҖеӨ§йҮҸзҡ„й«ҳе“ҒиҙЁзҡ„иө„ж–ҷгҖӮйүҙдәҺиҝҷдёҖзұ»зҡ„дҫӢеӯҗ,жҲ‘们и®Өдёәж ҮеҮҶзҡ„дҝЎжҒҜжЈҖзҙўе·ҘдҪңйңҖиҰҒжү©еӨ§иҢғеӣҙпјҢд»ҺиҖҢжңүж•ҲеӨ„зҗҶ WebгҖӮ
3.2 Webе’ҢеҸ—жҺ§йӣҶеҗҲзҡ„дёҚеҗҢ
дә’иҒ”зҪ‘ WebжҳҜдёҖдёӘе№ҝйҳ”зҡ„е……ж»Ўе®Ңе…ЁдёҚеҸ—жҺ§еҲ¶зҡ„ејӮжһ„ж–Ү件зҡ„йӣҶеҗҲгҖӮWeb дёҠзҡ„ж–Ү件,дёҚдҪҶеҶ…йғЁж јејҸжһҒе…¶дёҚеҗҢ,иҖҢдё”еӨ–йғЁе…ғдҝЎжҒҜд№ҹжңӘеҝ…еҸҜз”ЁгҖӮдҫӢеҰӮ,ж–Ү件еҶ…йғЁзҡ„дёҚеҗҢ,жңүеҗ„иҮӘзҡ„иҜӯиЁҖ(еҢ…жӢ¬иҮӘ然иҜӯиЁҖе’Ңзј–зЁӢиҜӯиЁҖ),еҗ„иҮӘзҡ„иҜҚжұҮ(з”өеӯҗйӮ®д»¶ең°еқҖ,й“ҫжҺҘ,йӮ®зј–,з”өиҜқеҸ·з Ғ,дә§е“ҒеҸ·з Ғ)пјҢж–Үд»¶ж јејҸзҡ„дёҚеҗҢ(ж–Үжң¬ж јејҸ, htmlж јејҸ, pdfж јејҸ,еӣҫеғҸж јејҸ,еЈ°йҹіж јејҸ),并且з”ҡиҮіеҸҜиғҪжҳҜжңәеҷЁдә§з”ҹзҡ„(ж—Ҙеҝ—ж–Ү件жҲ–иҖ…ж•°жҚ®еә“зҡ„иҫ“еҮәж–Ү件) гҖӮеңЁеҸҰдёҖж–№йқў,жҲ‘们е®ҡд№үж–Ү件зҡ„еӨ–йғЁе…ғдҝЎжҒҜпјҢд»ҺиҝҷдәӣдҝЎжҒҜе°ұеҸҜд»ҘжҺЁж–ӯеҮәдёҖдёӘж–Ү件зҡ„еӨ§жҰӮ,дҪҶжҳҜе…ғдҝЎжҒҜ并дёҚеҢ…еҗ«еңЁж–Ү件дёӯгҖӮж–Ү件еӨ–йғЁе…ғдҝЎжҒҜзҡ„дҫӢеӯҗ,еҢ…жӢ¬иҝҷж ·дёҖдәӣдҝЎжҒҜпјҡ жқҘжәҗзҡ„еЈ°иӘү,жӣҙж–°йў‘зҺҮ,иҙЁйҮҸ,еҸ—ж¬ўиҝҺзЁӢеәҰ е’Ң з”Ёжі• , е’Ңеј•з”ЁгҖӮдёҚд»…жҳҜеӨ–йғЁе…ғдҝЎжҒҜзҡ„еҸҜиғҪжқҘжәҗеҚғе·®дёҮеҲ«,иҖҢдё”иЎЎйҮҸзҡ„ж–№ејҸд№ҹеӯҳеңЁеҫҲеӨҡдёҚеҗҢж•°йҮҸзә§зҡ„е·®ејӮгҖӮдёҫдҫӢжқҘиҜҙ,жҜ”иҫғд»ҺдёҖдёӘеӨ§еһӢзҪ‘з«ҷзҡ„дё»йЎөеҫ—еҲ°зҡ„дҪҝз”ЁдҝЎжҒҜ,еҰӮпјҢйӣ…иҷҺпјҢзӣ®еүҚжҜҸеӨ©иҺ·еҫ—еҮ зҷҫдёҮзҡ„йЎөйқўжөҸи§ҲйҮҸпјҢ иҖҢдёҖдёӘжҷҰ涩зҡ„еҺҶеҸІж–Үз« ,еҸҜиғҪжҜҸ10е№ҙжүҚиғҪиў«жөҸи§ҲдёҖж¬ЎгҖӮжҳҫиҖҢжҳ“и§Ғ,жҗңзҙўеј•ж“Һеҝ…йЎ»дёҘйҮҚеҢәеҲ«еҜ№еҫ…иҝҷдёӨдёӘжқЎзӣ®гҖӮ
еҸҰдёҖдёӘWeb е’ҢеҸ—жҺ§йӣҶеҗҲзҡ„иҫғеӨ§е·®ејӮжҳҜ,еҮ д№ҺжІЎжңүйҷҗеҲ¶жҺ§еҲ¶дәә们еңЁзҪ‘дёҠеҸҜд»Ҙж”ҫд»Җд№ҲгҖӮжҠҠиҝҷз§ҚзҒөжҙ»жҖ§зҡ„еҶ…е®№еҸ‘еёғе’Ңдә§з”ҹе·ЁеӨ§еҪұе“Қзҡ„жҗңзҙўеј•ж“Һз»“еҗҲиө·жқҘ пјҢеҺ»еҗёеј•и®ҝй—®жөҸи§ҲйҮҸгҖӮ 并且еҫҲеӨҡе…¬еҸёйҖҡиҝҮж•…ж„Ҹж“Қзәөжҗңзҙўеј•ж“ҺжқҘиөўеҲ©пјҢж—ҘзӣҠжҲҗдёәдёҖдёӘдёҘйҮҚй—®йўҳгҖӮиҝҷдёӘй—®йўҳеңЁдј з»ҹзҡ„е°Ғй—ӯзҡ„дҝЎжҒҜжЈҖзҙўзі»з»ҹдёӯдёҖзӣҙжІЎжңүеҸ‘зҺ° гҖӮеҸҰеӨ–,жңүи¶Јзҡ„жҳҜжҲ‘们注ж„ҸеҲ°webжҗңзҙўеј•ж“ҺдҪҝеҫ—жғійҖҡиҝҮе…ғж•°жҚ®ж“Қзәөжҗңзҙўеј•ж“Һзҡ„еҠӘеҠӣеҹәжң¬дёҠеӨұиҙҘдәҶ,еӣ дёәзҪ‘йЎөдёҠзҡ„д»»дҪ•ж–Үеӯ—еҰӮжһңдёҚжҳҜз”ЁжқҘе‘ҲзҺ°з»ҷз”ЁжҲ·зҡ„пјҢ е°ұжҳҜиў«ж»Ҙз”ЁжқҘж“Қзәөжҗңзҙўеј•ж“ҺгҖӮз”ҡиҮіжңүи®ёеӨҡе…¬еҸёдё“й—Ёж“Қзәөжҗңзҙўеј•ж“Һд»ҘиҫҫеҲ°иөўеҲ©зҡ„зӣ®зҡ„гҖӮ
пјҲж–ӯж–ӯз»ӯз»ӯең°жҠҠе®ғзҝ»е®ҢдәҶгҖӮ第4йғЁеҲҶжҳҜGoogleжҗңзҙўеј•ж“ҺжңҖж ёеҝғзҡ„дёҖеқ—пјҢжңүдёҖдәӣи®ҫи®Ўз»ҶиҠӮиҝҳдёҚжҳҜеҫҲжҮӮпјҢеёҢжңӣиғҪе’ҢеӨ§е®¶дёҖиө·жҺўи®ЁгҖӮзҝ»иҜ‘дёҚеҪ“д№ӢеӨ„иҝҳиҜ·еҗ„дҪҚжҢҮеҮәпјҢи°ўи°ўгҖӮпјү
4 зі»з»ҹеү–жһҗпјҲSystem Anatomyпјү
йҰ–е…ҲпјҢжҲ‘们еҜ№жһ¶жһ„еҒҡдёҖдёӘй«ҳеұӮзҡ„и®Ёи®әгҖӮжҺҘзқҖпјҢеҜ№йҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„жңүдёҖдёӘж·ұе…Ҙзҡ„жҸҸиҝ°гҖӮжңҖеҗҺпјҢжҲ‘们е°Ҷж·ұе…ҘеҲҶжһҗдё»иҰҒзҡ„еә”з”ЁзЁӢеәҸпјҡзҲ¬иҷ«пјҢзҙўеј•е’ҢжҗңзҙўгҖӮ
4.1 Googleжһ¶жһ„жҰӮиҝ°
еӣҫ1. Googleй«ҳеұӮжһ¶жһ„
еңЁиҝҷдёҖйғЁеҲҶпјҢжҲ‘们е°ҶеҜ№еӣҫ1дёӯж•ҙдёӘзі»з»ҹжҳҜжҖҺд№ҲиҝҗиЎҢзҡ„жңүдёҖдёӘй«ҳеұӮзҡ„жҰӮиҝ°гҖӮиҝҷдёҖйғЁеҲҶжІЎжңүжҸҗеҲ°еә”з”ЁзЁӢеәҸе’Ңж•°жҚ®з»“жһ„пјҢиҝҷдәӣдјҡеңЁжҺҘдёӢжқҘзҡ„еҮ йғЁеҲҶйҮҢи®Ёи®әгҖӮиҖғиҷ‘еҲ°ж•ҲзҺҮпјҢGoogleзҡ„еӨ§йғЁеҲҶжҳҜз”ЁCжҲ–C++е®һзҺ°пјҢеҸҜд»ҘеңЁSolarisжҲ–иҖ…LinuxдёӢиҝҗиЎҢгҖӮ
еңЁGoogleдёӯпјҢзҪ‘йЎөжҠ“еҸ–пјҲдёӢиҪҪwebйЎөйқўпјүзҡ„е·ҘдҪңз”ұеҲҶеёғејҸзҡ„зҲ¬иҷ«пјҲcrawlersпјүе®ҢжҲҗгҖӮжңүдёҖдёӘURLжңҚеҠЎеҷЁпјҲеӣҫ1дёӯзҡ„URL ServerпјүжҠҠйңҖиҰҒжҠ“еҸ–зҡ„URLеҲ—иЎЁеҸ‘йҖҒз»ҷзҲ¬иҷ«гҖӮзҪ‘йЎөжҠ“еҸ–еҘҪд№ӢеҗҺиў«еҸ‘йҖҒеҲ°еӯҳеӮЁжңҚеҠЎеҷЁпјҲеӣҫ1дёӯзҡ„Store ServerпјүгҖӮжҺҘзқҖеӯҳеӮЁжңҚеҠЎеҷЁе°ҶжҠ“еҸ–жқҘзҡ„зҪ‘йЎөеҺӢ缩并еӯҳж”ҫеңЁд»“еә“(repository)йҮҢгҖӮжҜҸдёҖдёӘзҪ‘йЎөйғҪжңүдёҖдёӘдёҺд№Ӣзӣёе…ізҡ„IDпјҢеҸ«docIDгҖӮеңЁдёҖдёӘзҪ‘йЎөйҮҢжҜҸеҸ‘зҺ°дёҖдёӘж–°зҡ„URLпјҢе°ұдјҡиөӢдәҲе®ғдёҖдёӘIDгҖӮзҙўеј•еҠҹиғҪз”ұзҙўеј•еҷЁпјҲеӣҫ1дёӯзҡ„indexerпјүе’ҢжҺ’еәҸеҷЁпјҲеӣҫ1дёӯзҡ„sorterпјүе®ҢжҲҗгҖӮзҙўеј•еҷЁжңүеҫҲеӨҡеҠҹиғҪгҖӮе®ғд»Һд»“еә“дёӯиҜ»еҸ–пјҢи§ЈеҺӢ并еҲҶжһҗж–ҮжЎЈгҖӮжҜҸдёӘж–ҮжЎЈйғҪиў«иҪ¬еҢ–жҲҗдёҖдёӘиҜҚзҡ„йӣҶеҗҲпјҢиҜҚеҮәзҺ°дёҖж¬ЎеҸ«еҒҡдёҖдёӘе‘ҪдёӯпјҲhitsпјүгҖӮжҜҸжқЎе‘Ҫдёӯи®°еҪ•дәҶдёҖдёӘиҜҚпјҢиҝҷдёӘиҜҚеңЁж–ҮжЎЈдёӯзҡ„дҪҚзҪ®пјҢеӯ—дҪ“еӨ§е°Ҹзҡ„иҝ‘дјјеҖјд»ҘеҸҠеӨ§е°ҸеҶҷдҝЎжҒҜгҖӮзҙўеј•еҷЁе°Ҷиҝҷдәӣе‘ҪдёӯеҲҶеёғеҲ°дёҖзі»еҲ—вҖңжЎ¶вҖқпјҲbarrelsпјүйҮҢйқўпјҢе»әз«ӢдёҖдёӘеҚҠжҺ’еәҸ(partially sorted)зҡ„жӯЈжҺ’зҙўеј•(forward index)гҖӮзҙўеј•еҷЁиҝҳжңүдёҖдёӘйҮҚиҰҒзҡ„еҠҹиғҪгҖӮе®ғи§ЈжһҗеҮәжҜҸеј зҪ‘йЎөйҮҢйқўзҡ„жүҖжңүй“ҫжҺҘпјҢ并жҠҠиҝҷдәӣй“ҫжҺҘзҡ„зӣёе…ійҮҚиҰҒдҝЎжҒҜеӯҳж”ҫеңЁдёҖдёӘй”ҡ(anchors)ж–Ү件йҮҢгҖӮиҝҷдёӘж–Ү件еҢ…еҗ«дәҶи¶іеӨҹзҡ„дҝЎжҒҜпјҢд»ҘжҳҫзӨәжҜҸдёӘй“ҫжҺҘд»Һе“ӘйҮҢиҝһжҺҘиҝҮжқҘпјҢй“ҫеҲ°е“ӘйҮҢе’Ңй“ҫжҺҘзҡ„жҸҸиҝ°гҖӮ
URLеҲҶи§ЈеҷЁпјҲURLresolverпјүиҜ»еҸ–й”ҡж–Ү件пјҢе°ҶзӣёеҜ№URLиҪ¬еҢ–дёәз»қеҜ№URLпјҢеҶҚиҪ¬еҢ–жҲҗdocIDгҖӮе®ғдёәй”ҡж–Үжң¬е»әз«ӢдёҖдёӘжӯЈжҺ’зҙўеј•пјҢ并дёҺй”ҡжҢҮеҗ‘зҡ„docIDе…іиҒ”иө·жқҘгҖӮе®ғиҝҳдә§з”ҹдёҖдёӘжңүdocIDеҜ№з»„жҲҗзҡ„й“ҫжҺҘж•°жҚ®еә“гҖӮиҝҷдёӘй“ҫжҺҘж•°жҚ®еә“е“ҹеҠҹиғҪжқҘи®Ўз®—жүҖжңүж–Ү件зҡ„PageRankеҖјгҖӮ
жҺ’еәҸеҷЁ(sorter)еҜ№жҢүз…§docIDжҺ’еәҸзҡ„(иҝҷйҮҢеҒҡдәҶз®ҖеҢ–пјҢиҜҰжғ…и§Ғ4.2.5е°ҸиҠӮ)вҖңжЎ¶вҖқ(barrels)йҮҚж–°жҢүз…§wordIDжҺ’еәҸпјҢз”ЁдәҺдә§з”ҹеҖ’жҺ’зҙўеј•(inverted index)гҖӮиҝҷдёӘж“ҚдҪңеңЁжҒ°еҪ“зҡ„ж—¶еҖҷиҝӣиЎҢпјҢжүҖд»ҘйңҖиҰҒеҫҲе°‘зҡ„жҡӮеӯҳз©әй—ҙгҖӮжҺ’еәҸеҷЁиҝҳеңЁеҖ’жҺ’зҙўеј•дёӯе»әз«ӢдёҖдёӘwordIDе’ҢеҒҸ移йҮҸзҡ„еҲ—иЎЁгҖӮдёҖдёӘеҸ«DumpLexiconзҡ„зЁӢеәҸжҠҠиҝҷдёӘеҲ—иЎЁдёҺз”ұзҙўеј•еҷЁдә§з”ҹзҡ„иҜҚе…ёз»“еҗҲиө·жқҘпјҢз”ҹжҲҗдёҖдёӘж–°зҡ„иҜҚе…ёпјҢдҫӣжҗңзҙўеҷЁпјҲsearcherпјүдҪҝз”ЁгҖӮжҗңзҙўеҷЁз”ұдёҖдёӘWebжңҚеҠЎеҷЁиҝҗиЎҢпјҢж №жҚ®DumpLexiconдә§з”ҹзҡ„иҜҚе…ёпјҢеҖ’жҺ’зҙўеј•е’ҢPageRankеҖјжқҘеӣһзӯ”жҹҘиҜўгҖӮ
4.2 дё»иҰҒзҡ„ж•°жҚ®з»“жһ„
Googleзҡ„ж•°жҚ®з»“жһ„з»ҸиҝҮдәҶдјҳеҢ–пјҢиҝҷж ·еӨ§йҮҸзҡ„ж–ҮжЎЈиғҪеӨҹеңЁиҫғдҪҺзҡ„жҲҗжң¬дёӢиў«жҠ“еҸ–пјҢзҙўеј•е’ҢжҗңзҙўгҖӮе°Ҫз®ЎCPUе’ҢI/OйҖҹзҺҮиҝҷдәӣе№ҙд»ҘжғҠдәәзҡ„йҖҹеәҰеўһй•ҝпјҢдҪҶжҳҜжҜҸдёҖдёӘзЈҒзӣҳжҹҘжүҫж“ҚдҪңд»ҚйңҖиҰҒеӨ§жҰӮ10еҫ®з§’жүҚиғҪе®ҢжҲҗгҖӮGoogleеңЁи®ҫи®Ўж—¶е°ҪйҮҸйҒҝе…ҚзЈҒзӣҳжҹҘжүҫпјҢиҝҷдёҖи®ҫи®Ўд№ҹеӨ§еӨ§еҪұе“ҚдәҶж•°жҚ®з»“жһ„зҡ„и®ҫи®ЎгҖӮ
4.2.1 BigFiles
BigFilesжҳҜеҲҶеёғеңЁдёҚеҗҢж–Ү件系з»ҹдёӢйқўзҡ„иҷҡжӢҹж–Ү件пјҢйҖҡиҝҮ64дҪҚж•ҙж•°еҜ»еқҖгҖӮиҷҡжӢҹж–Ү件被иҮӘеҠЁеҲҶй…ҚеҲ°дёҚеҗҢж–Ү件系з»ҹгҖӮBigFilesзҡ„еҢ…иҝҳиҙҹиҙЈеҲҶй…Қе’ҢйҮҠж”ҫж–Ү件жҸҸиҝ°з¬ҰпјҲиҜ‘иҖ…жіЁпјҡзүөж¶үеҲ°ж“ҚдҪңзі»з»ҹеә•еұӮпјүпјҢеӣ дёәж“ҚдҪңзі»з»ҹжҸҗдҫӣзҡ„еҠҹиғҪ并дёҚиғҪж»Ўи¶іжҲ‘们зҡ„иҰҒжұӮгҖӮBigFilesиҝҳж”ҜжҢҒеҹәжң¬зҡ„еҺӢзј©йҖүйЎ№гҖӮ
4.2.2 ж•°жҚ®д»“еә“пјҲRepositoryпјү
еӣҫ2. ж•°жҚ®д»“еә“зҡ„з»“жһ„
ж•°жҚ®д»“еә“еҢ…жӢ¬дәҶжҜҸдёӘwebйЎөйқўзҡ„ж•ҙдёӘHTMLд»Јз ҒгҖӮжҜҸдёӘйЎөйқўз”ЁzlibпјҲеҸӮи§ҒRFC1950пјүеҺӢзј©гҖӮеҺӢзј©жҠҖжңҜзҡ„йҖүжӢ©жҳҜйҖҹеәҰе’ҢеҺӢзј©жҜ”зҡ„дёҖдёӘжқғиЎЎгҖӮжҲ‘们йҖүжӢ©zlibжҳҜеӣ дёәе®ғзҡ„еҺӢзј©йҖҹеәҰиҰҒжҜ”bzipеҝ«еҫҲеӨҡгҖӮеңЁж•°жҚ®д»“еә“дёҠпјҢbzipзҡ„еҺӢзј©жҜ”жҳҜ4пјҡ1пјҢиҖҢzlibзҡ„жҳҜ3пјҡ1гҖӮеңЁж•°жҚ®д»“еә“дёӯпјҢж–ҮжЎЈдёҖдёӘдёҖдёӘиҝһжҺҘеӯҳж”ҫпјҢжҜҸдёӘж–ҮжЎЈжңүдёҖдёӘеүҚзјҖпјҢеҢ…жӢ¬docIDпјҢй•ҝеәҰе’ҢURLпјҲеҰӮеӣҫ2пјүгҖӮиҰҒи®ҝй—®иҝҷдәӣж–ҮжЎЈпјҢж•°жҚ®д»“еә“дёҚеҶҚйңҖиҰҒе…¶д»–зҡ„ж•°жҚ®з»“жһ„гҖӮиҝҷдҪҝеҫ—дҝқжҢҒж•°жҚ®дёҖиҮҙжҖ§е’ҢејҖеҸ‘йғҪжӣҙз®ҖеҚ•пјӣжҲ‘们еҸҜд»Ҙд»…д»…йҖҡиҝҮж•°жҚ®д»“еә“е’ҢдёҖдёӘи®°еҪ•зҲ¬иҷ«й”ҷиҜҜдҝЎжҒҜзҡ„ж–Ү件жқҘйҮҚе»әе…¶д»–жүҖжңүзҡ„ж•°жҚ®з»“жһ„гҖӮ
4.2.3 ж–ҮжЎЈзҙўеј•пјҲDocument Indexпјү
ж–ҮжЎЈзҙўеј•дҝқеӯҳдәҶжҜҸдёӘж–ҮжЎЈзҡ„дҝЎжҒҜгҖӮе®ғжҳҜдёҖдёӘж №жҚ®docIDжҺ’еәҸзҡ„е®ҡй•ҝ(fixed width)ISAMпјҲзҙўеј•йЎәеәҸи®ҝй—®жЁЎејҸIndex sequential access modeпјүзҙўеј•гҖӮиҝҷдәӣдҝЎжҒҜиў«еӯҳж”ҫеңЁжҜҸдёӘжқЎзӣ®(entry)йҮҢйқўпјҢеҢ…жӢ¬еҪ“еүҚж–ҮжЎЈзҠ¶жҖҒпјҢжҢҮеҗ‘ж•°жҚ®д»“еә“зҡ„жҢҮй’ҲпјҢж–ҮжЎЈж ЎйӘҢе’Ң(checksum)е’Ңеҗ„з§Қз»ҹи®Ўж•°жҚ®гҖӮеҰӮжһңж–ҮжЎЈе·Із»Ҹиў«жҠ“еҸ–дәҶпјҢе®ғиҝҳдјҡеҢ…жӢ¬дёҖдёӘжҢҮй’ҲпјҢиҝҷдёӘжҢҮй’ҲжҢҮеҗ‘дёҖдёӘеҸ«docinfoзҡ„еҸҳй•ҝ(variable width)ж–Ү件пјҢйҮҢйқўи®°еҪ•дәҶж–ҮжЎЈзҡ„URLе’Ңж ҮйўҳгҖӮеҗҰеҲҷпјҢиҝҷдёӘжҢҮй’Ҳе°ҶжҢҮеҗ‘дёҖдёӘURLеҲ—иЎЁпјҢйҮҢйқўеҸӘжңүURLгҖӮиҝҷж ·и®ҫи®Ўзҡ„зӣ®зҡ„жҳҜдёәдәҶжңүдёҖдёӘзӣёеҜ№зҙ§еҮ‘зҡ„ж•°жҚ®з»“жһ„пјҢеңЁдёҖж¬Ўжҗңзҙўж“ҚдҪңдёӯеҸӘйңҖиҰҒдёҖж¬ЎзЈҒзӣҳжҹҘжүҫе°ұиғҪеҸ–еҮәдёҖжқЎи®°еҪ•гҖӮ
еҸҰеӨ–пјҢиҝҳжңүдёҖдёӘж–Ү件用жқҘе°ҶURLиҪ¬еҢ–жҲҗdocIDгҖӮиҝҷдёӘж–Ү件жҳҜдёҖдёӘеҲ—иЎЁпјҢеҢ…жӢ¬URLж ЎйӘҢе’Ң(checksum)е’ҢеҜ№еә”зҡ„docIDпјҢж №жҚ®ж ЎйӘҢе’ҢжҺ’еәҸгҖӮдёәдәҶжүҫеҲ°жҹҗдёҖдёӘURLзҡ„docIDпјҢйҰ–е…Ҳи®Ўз®—URLзҡ„ж ЎйӘҢе’ҢпјҢ然еҗҺеңЁж ЎйӘҢе’Ңж–Ү件йҮҢеҒҡдёҖж¬ЎдәҢеҲҶжҹҘжүҫпјҢжүҫеҲ°е®ғзҡ„docIDгҖӮURLиҪ¬еҢ–жҲҗdocIDжҳҜйҖҡиҝҮж–Ү件еҗҲ并жү№йҮҸж“ҚдҪңзҡ„гҖӮиҝҷдёӘжҠҖжңҜжҳҜеңЁURLеҲҶи§ЈеҷЁпјҲURL resolverпјүжҠҠURLиҪ¬еҢ–жҲҗdocIDж—¶дҪҝз”Ёзҡ„гҖӮиҝҷз§Қжү№йҮҸжӣҙж–°зҡ„жЁЎејҸеҫҲе…ій”®пјҢеӣ дёәеҰӮжһңжҲ‘们дёәжҜҸдёӘй“ҫжҺҘеҒҡдёҖж¬ЎзЈҒзӣҳжҹҘжүҫпјҢдёҖдёӘзЈҒзӣҳйңҖиҰҒ1дёӘжңҲзҡ„ж—¶й—ҙжүҚиғҪдёәжҲ‘们зҡ„3.22дәҝжқЎй“ҫжҺҘзҡ„ж•°жҚ®йӣҶе®ҢжҲҗжӣҙж–°гҖӮ
4.2.4 иҜҚе…ёпјҲLexiconпјү
иҜҚе…ёеӨҡз§ҚдёҚеҗҢж јејҸгҖӮдёҺж—©еүҚзҡ„зі»з»ҹзӣёжҜ”пјҢдёҖдёӘйҮҚиҰҒзҡ„еҸҳеҢ–жҳҜзҺ°еңЁзҡ„иҜҚе…ёеҸҜд»Ҙд»ҘеҗҲзҗҶзҡ„жҲҗжң¬е…ЁйғЁж”ҫеңЁеҶ…еӯҳйҮҢйқўгҖӮзӣ®еүҚзҡ„е®һзҺ°дёӯпјҢжҲ‘们жҠҠиҜҚе…ёж”ҫеңЁдёҖдёӘ256Mзҡ„дё»еӯҳйҮҢйқўгҖӮзҺ°еңЁзҡ„иҜҚе…ёжңү1.4еҚғдёҮеҚ•иҜҚпјҲе°Ҫз®ЎдёҖдәӣйқһеёёз”ЁиҜҚжІЎжңүиў«еҢ…еҗ«иҝӣжқҘпјүгҖӮе®ғз”ұдёӨйғЁеҲҶе®һзҺ°вҖ”вҖ”дёҖдёӘеҚ•иҜҚеҲ—иЎЁпјҲиҝһжҺҘеңЁдёҖиө·пјҢдҪҶжҳҜйҖҡиҝҮз©әзҷҪnullsеҲҶејҖпјүе’ҢдёҖдёӘжҢҮй’Ҳзҡ„е“ҲеёҢиЎЁ(hash table)гҖӮеҚ•иҜҚеҲ—иЎЁиҝҳжңүдёҖдәӣйҷ„еҠ дҝЎжҒҜпјҢдҪҶжҳҜиҝҷдәӣдёҚеңЁжң¬зҜҮж–Үз« зҡ„и®Ёи®әиҢғеӣҙгҖӮ
4.2.5 е‘ҪдёӯеҲ—иЎЁпјҲHit Listsпјү
дёҖдёӘе‘ҪдёӯеҲ—иЎЁеҜ№еә”зқҖдёҖдёӘеҚ•иҜҚеңЁдёҖдёӘж–ҮжЎЈдёӯеҮәзҺ°зҡ„дҪҚзҪ®гҖҒеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜзҡ„еҲ—иЎЁгҖӮе‘ҪдёӯеҲ—иЎЁеҚ з”ЁдәҶжӯЈжҺ’зҙўеј•е’ҢеҖ’жҺ’зҙўеј•зҡ„еӨ§йғЁеҲҶз©әй—ҙпјҢжүҖд»ҘжҖҺж ·е°ҪеҸҜиғҪжңүж•Ҳзҡ„иЎЁзӨәжҳҜеҫҲйҮҚиҰҒзҡ„гҖӮжҲ‘们иҖғиҷ‘дәҶеҜ№дҪҚзҪ®пјҢеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜзҡ„еӨҡз§Қзј–з Ғж–№ејҸвҖ”вҖ”з®ҖеҚ•зј–з ҒпјҲ3дёӘж•ҙж•°пјүпјҢеҺӢзј©зј–з ҒпјҲжүӢе·ҘдјҳеҢ–еҲҶй…ҚжҜ”зү№пјүе’ҢйңҚеӨ«жӣјзј–з ҒпјҲHuffman codingпјүгҖӮе‘ҪдёӯпјҲhitпјүзҡ„иҜҰжғ…и§Ғеӣҫ3гҖӮ
еӣҫ3. жӯЈгҖҒеҖ’жҺ’зҙўеј•е’ҢиҜҚе…ё
жҲ‘们зҡ„еҺӢзј©зј–з ҒжҜҸдёӘе‘Ҫдёӯз”ЁеҲ°дёӨдёӘеӯ—иҠӮ(byte)гҖӮжңүдёӨз§Қе‘Ҫдёӯпјҡзү№ж®Ҡе‘ҪдёӯпјҲfancy hitпјүе’Ңжҷ®йҖҡе‘ҪдёӯпјҲplain hitпјүгҖӮзү№ж®Ҡе‘ҪдёӯеҢ…жӢ¬еңЁURLпјҢж ҮйўҳпјҢй”ҡж–Үжң¬е’Ңmetaж ҮзӯҫдёҠзҡ„е‘ҪдёӯгҖӮе…¶д»–зҡ„йғҪжҳҜжҷ®йҖҡе‘ҪдёӯгҖӮдёҖдёӘжҷ®йҖҡзҡ„е‘ҪдёӯеҢ…жӢ¬дёҖдёӘиЎЁзӨәеӨ§е°ҸеҶҷзҡ„жҜ”зү№(bit)пјҢеӯ—дҪ“еӨ§е°ҸпјҢе’Ң12дёӘbitиЎЁзӨәзҡ„еҚ•иҜҚеңЁж–Ү件дёӯзҡ„дҪҚзҪ®пјҲжүҖжңүжҜ”4095еӨ§зҡ„дҪҚзҪ®йғҪиў«ж ҮзӨәдёә4096пјүгҖӮеӯ—дҪ“еңЁж–ҮжЎЈдёӯзҡ„зӣёеҜ№еӨ§е°Ҹз”Ё3дёӘжҜ”зү№иЎЁзӨәпјҲе®һйҷ…дёҠеҸӘз”ЁеҲ°7дёӘеҖјпјҢеӣ дёә111ж ҮзӨәдёҖдёӘзү№ж®Ҡе‘ҪдёӯпјүгҖӮдёҖдёӘзү№ж®Ҡе‘ҪдёӯеҢ…еҗ«дёҖдёӘеӨ§е°ҸеҶҷжҜ”зү№пјҢеӯ—дҪ“еӨ§е°Ҹи®ҫзҪ®дёә7з”ЁжқҘиЎЁзӨәе®ғжҳҜдёҖдёӘзү№ж®Ҡе‘ҪдёӯпјҢ4дёӘжҜ”зү№з”ЁжқҘиЎЁзӨәзү№ж®Ҡе‘Ҫдёӯзҡ„зұ»еһӢпјҢ8дёӘжҜ”зү№иЎЁзӨәдҪҚзҪ®гҖӮеҜ№дәҺй”ҡе‘ҪдёӯпјҢиЎЁзӨәдҪҚзҪ®зҡ„8дёӘжҜ”зү№иў«еҲҶжҲҗдёӨйғЁеҲҶпјҢ4дёӘжҜ”зү№иЎЁзӨәеңЁй”ҡж–Үжң¬дёӯзҡ„дҪҚзҪ®пјҢ4дёӘжҜ”зү№дёәй”ҡж–Үжң¬жүҖеңЁdocIDзҡ„е“ҲеёҢпјҲhashпјүеҖјгҖӮз”ұдәҺдёҖдёӘиҜҚ并没жңүйӮЈд№ҲеӨҡзҡ„й”ҡж–Үжң¬пјҢжүҖд»ҘзҹӯиҜӯжҗңзҙўеҸ—еҲ°дёҖдәӣйҷҗеҲ¶гҖӮжҲ‘们жңҹжңӣиғҪжӣҙж–°й”ҡе‘Ҫдёӯзҡ„еӯҳеӮЁж–№ејҸиғҪи®©дҪҚзҪ®е’ҢdocIDе“ҲеёҢеҖјиғҪжңүжӣҙеӨ§зҡ„иҢғеӣҙгҖӮжҲ‘们дҪҝз”ЁеңЁдёҖдёӘж–ҮжЎЈдёӯзҡ„зӣёеҜ№еӯ—дҪ“еӨ§е°ҸжҳҜеӣ дёәеңЁжҗңзҙўж—¶пјҢдҪ 并дёҚеёҢжңӣеҜ№дәҺеҶ…е®№зӣёеҗҢзҡ„дёҚеҗҢж–ҮжЎЈпјҢд»…д»…еӣ дёәдёҖдёӘж–ҮжЎЈеӯ—дҪ“жҜ”иҫғеӨ§иҖҢжңүжӣҙй«ҳзҡ„иҜ„зә§пјҲrankпјүгҖӮ
е‘ҪдёӯеҲ—иЎЁзҡ„й•ҝеәҰеӯҳеңЁе‘Ҫдёӯзҡ„еүҚйқўгҖӮдёәдәҶиҠӮзңҒз©әй—ҙпјҢе‘ҪдёӯеҲ—иЎЁзҡ„й•ҝеәҰеңЁжӯЈжҺ’зҙўеј•дёӯдёҺwordIDз»“еҗҲпјҢеңЁеҖ’жҺ’зҙўеј•дёӯдёҺdocIDз»“еҗҲгҖӮиҝҷж ·е°ұе°Ҷй•ҝеәҰеҲҶеҲ«йҷҗеҲ¶еңЁ8дёӘжҜ”зү№е’Ң5дёӘжҜ”зү№пјҲжңүдёҖдәӣжҠҖе·§еҸҜд»Ҙд»ҺwordIDдёӯеҖҹз”Ё8дёӘжҜ”зү№пјүгҖӮеҰӮжһңй•ҝеәҰи¶…иҝҮдәҶиҝҷдёӘиҢғеӣҙпјҢдјҡеңЁиҝҷдәӣжҜ”зү№дёӯдҪҝз”ЁиҪ¬д№үз ҒпјҢеңЁжҺҘдёӢжқҘзҡ„дёӨдёӘеӯ—иҠӮ(byte)йҮҢжүҚеӯҳж”ҫзңҹжӯЈзҡ„й•ҝеәҰгҖӮ
4.2.6 жӯЈжҺ’зҙўеј•пјҲForward Indexпјү
жӯЈжҺ’зҙўеј•е®һйҷ…дёҠе·Із»ҸйғЁеҲҶжҺ’еәҸпјҲpartially sortedпјүгҖӮе®ғиў«еӯҳж”ҫеңЁдёҖзі»еҲ—зҡ„жЎ¶пјҲbarrelsпјүйҮҢйқўпјҲжҲ‘们用дәҶ64дёӘпјүгҖӮжҜҸдёӘжЎ¶дҝқеӯҳдәҶдёҖе®ҡиҢғеӣҙеҶ…зҡ„wordIDгҖӮеҰӮжһңдёҖдёӘж–ҮжЎЈеҢ…еҗ«дәҶеұһдәҺжҹҗдёӘжЎ¶зҡ„еҚ•иҜҚпјҢе®ғзҡ„docIDе°Ҷиў«и®°еҪ•еңЁжЎ¶йҮҢйқўпјҢеҗҺйқўжҺҘзқҖдёҖдёӘwordIDзҡ„еҲ—иЎЁе’Ңзӣёеә”зҡ„е‘ҪдёӯеҲ—иЎЁгҖӮиҝҷз§Қз»“жһ„йңҖиҰҒдёҖзӮ№еӨҡдҪҷз©әй—ҙпјҢеӣ дёәеӯҳеӮЁдәҶйҮҚеӨҚзҡ„docIDпјҢз”ұдәҺжЎ¶зҡ„ж•°йҮҸеҫҲе°ҸпјҢжүҖд»ҘеӯҳеӮЁз©әй—ҙзҡ„е·®еҲ«еҫҲе°ҸпјҢдҪҶжҳҜе®ғиғҪеңЁжҺ’еәҸеҷЁпјҲsorterпјүе»әз«ӢжңҖз»Ҳзҙўеј•зҡ„ж—¶еҖҷеӨ§еӨ§иҠӮзңҒж—¶й—ҙ并йҷҚдҪҺдәҶзЁӢеәҸеӨҚжқӮеәҰгҖӮжӣҙиҝӣдёҖжӯҘпјҢжҲ‘们并没жңүеӯҳеӮЁе®Ңж•ҙзҡ„wordIDпјҢиҖҢжҳҜеӯҳеӮЁжҜҸдёӘwordIDзӣёеҜ№дәҺе…¶еҜ№еә”зҡ„жЎ¶йҮҢйқўжңҖе°ҸwordIDзҡ„е·®и·қгҖӮиҝҷж ·жҲ‘们еҸӘз”ЁеҲ°дәҶ24дёӘжҜ”зү№пјҢд»ҺиҖҢдёәе‘ҪдёӯеҲ—иЎЁй•ҝеәҰпјҲhit list lengthпјүз•ҷеҮәдәҶ8дёӘжҜ”зү№гҖӮ
4.2.7 еҖ’жҺ’зҙўеј•пјҲInverted Indexпјү
еҖ’жҺ’зҙўеј•дёҺжӯЈжҺ’зҙўеј•жңүзқҖзӣёеҗҢзҡ„жЎ¶пјҢдҪҶжҳҜе®ғ们жҳҜе…Ҳз»ҸиҝҮжҺ’еәҸеҷЁеӨ„зҗҶиҝҮзҡ„гҖӮеҜ№жҜҸдёҖдёӘеҗҲжі•зҡ„wordIDпјҢиҜҚе…ёеҢ…еҗ«дәҶдёҖдёӘжҢҮеҗ‘еҜ№еә”зҡ„жЎ¶зҡ„жҢҮй’ҲгҖӮе®ғжҢҮеҗ‘дёҖдёӘdocIDзҡ„еҲ—иЎЁе’Ңзӣёеә”зҡ„е‘ҪдёӯеҲ—иЎЁгҖӮиҝҷдёӘж–ҮжЎЈеҲ—иЎЁжҳҫзӨәдәҶжңүиҝҷдёӘеҚ•иҜҚеҮәзҺ°зҡ„жүҖжңүж–ҮжЎЈгҖӮ
дёҖдёӘйҮҚиҰҒзҡ„дәӢжғ…жҳҜеҰӮдҪ•еҜ№иҝҷдёӘж–ҮжЎЈеҲ—иЎЁжҺ’еәҸгҖӮдёҖдёӘз®ҖеҚ•зҡ„ж–№жі•жҳҜжҢүз…§docIDжҺ’еәҸгҖӮеңЁеӨҡдёӘеҚ•иҜҚзҡ„жҹҘиҜўдёӯпјҢиҝҷз§Қж–№жі•еҸҜд»Ҙеҝ«йҖҹең°е®ҢжҲҗдёӨдёӘж–ҮжЎЈеҲ—иЎЁзҡ„еҪ’并гҖӮеҸҰдёҖз§Қж–№жЎҲжҳҜжҢүз…§иҝҷдёӘиҜҚеңЁж–ҮжЎЈдёӯеҮәзҺ°зҡ„иҜ„еҲҶ(ranking)жҺ’еәҸгҖӮиҝҷз§Қж–№ејҸдҪҝеҫ—еҚ•дёӘиҜҚзҡ„жҹҘиҜўзӣёеҪ“з®ҖеҚ•пјҢ并且еӨҡиҜҚжҹҘиҜўзҡ„иҝ”еӣһз»“жһңд№ҹеҫҲеҸҜиғҪжҺҘиҝ‘ејҖеӨҙпјҲиҜ‘иҖ…жіЁпјҡиҝҷеҸҘдёҚжҳҜеҫҲзҗҶи§ЈпјүгҖӮдҪҶжҳҜпјҢеҪ’并иҰҒеӣ°йҡҫеҫ—еӨҡгҖӮиҖҢдё”пјҢејҖеҸ‘д№ҹдјҡеӣ°йҡҫеҫ—еӨҡпјҢеӣ дёәжҜҸж¬ЎиҜ„еҲҶеҮҪж•°еҸҳеҠЁе°ұйңҖиҰҒйҮҚж–°е»әз«Ӣж•ҙдёӘзҙўеј•гҖӮжҲ‘们综еҗҲдәҶдёӨз§Қж–№жЎҲпјҢи®ҫи®ЎдәҶдёӨдёӘеҖ’жҺ’жЎ¶йӣҶеҗҲвҖ”вҖ”дёҖдёӘйӣҶеҗҲеҸӘеҢ…жӢ¬ж Үйўҳе’Ңй”ҡе‘ҪдёӯпјҲиҜ‘иҖ…жіЁпјҡеҗҺйқўз®Җз§°зҹӯжЎ¶пјүпјҢеҸҰдёҖдёӘйӣҶеҗҲеҢ…еҗ«жүҖжңүзҡ„е‘ҪдёӯпјҲиҜ‘иҖ…жіЁпјҡеҗҺйқўз®Җз§°е…ЁжЎ¶пјүгҖӮиҝҷж ·жҲ‘们йҰ–е…ҲжЈҖжҹҘ第дёҖдёӘжЎ¶йӣҶеҗҲпјҢеҰӮжһңжІЎжңүи¶іеӨҹзҡ„еҢ№й…ҚеҶҚжЈҖжҹҘйӮЈдёӘеӨ§дёҖзӮ№зҡ„гҖӮ
4.3 зҪ‘йЎөжҠ“еҸ–пјҲCrawling the Webпјү
иҝҗиЎҢзҪ‘з»ңзҲ¬иҷ«жҳҜдёҖйЎ№еҫҲжңүжҢ‘жҲҳжҖ§зҡ„д»»еҠЎгҖӮиҝҷйҮҢдёҚе…үж¶үеҸҠеҲ°е·§еҰҷзҡ„жҖ§иғҪе’ҢеҸҜйқ жҖ§й—®йўҳпјҢжӣҙйҮҚиҰҒзҡ„пјҢиҝҳжңүзӨҫдјҡй—®йўҳгҖӮжҠ“еҸ–жҳҜдёҖдёӘеҫҲи„Ҷејұзҡ„еә”з”ЁпјҢеӣ дёәе®ғйңҖиҰҒдёҺжҲҗзҷҫдёҠеҚғеҗ„з§Қеҗ„ж ·зҡ„webжңҚеҠЎеҷЁе’ҢеҹҹеҗҚжңҚеҠЎеҷЁдәӨдә’пјҢиҝҷдәӣйғҪдёҚеңЁзі»з»ҹзҡ„жҺ§еҲ¶иҢғеӣҙд№ӢеҶ…гҖӮ
дёәдәҶжҠ“еҸ–еҮ дәҝзҪ‘йЎөпјҢGoogleжңүдёҖдёӘеҝ«йҖҹзҡ„еҲҶеёғејҸзҲ¬иҷ«зі»з»ҹгҖӮдёҖдёӘеҚ•зӢ¬зҡ„URLжңҚеҠЎеҷЁпјҲURLserverпјүдёәеӨҡдёӘзҲ¬иҷ«(crawler,дёҖиҲ¬жҳҜ3дёӘ)жҸҗдҫӣURLеҲ—иЎЁгҖӮURLжңҚеҠЎеҷЁе’ҢзҲ¬иҷ«йғҪз”ЁPythonе®һзҺ°гҖӮжҜҸдёӘзҲ¬иҷ«еҗҢж—¶жү“ејҖеӨ§жҰӮ300дёӘиҝһжҺҘ(connecton)гҖӮиҝҷж ·жүҚиғҪдҝқиҜҒи¶іеӨҹеҝ«ең°жҠ“еҸ–йҖҹеәҰгҖӮеңЁй«ҳеі°ж—¶жңҹпјҢзі»з»ҹйҖҡиҝҮ4дёӘзҲ¬иҷ«жҜҸз§’й’ҹзҲ¬еҸ–100дёӘзҪ‘йЎөгҖӮиҝҷеӨ§жҰӮжңү600KжҜҸз§’зҡ„ж•°жҚ®дј иҫ“гҖӮдёҖдёӘдё»иҰҒзҡ„жҖ§иғҪеҺӢеҠӣеңЁDNSжҹҘиҜў(lookup)гҖӮжҜҸдёӘзҲ¬иҷ«йғҪз»ҙжҠӨдёҖдёӘиҮӘе·ұзҡ„DNSзј“еӯҳпјҢиҝҷж ·еңЁе®ғжҠ“еҸ–зҪ‘йЎөд№ӢеүҚе°ұдёҚеҶҚйңҖиҰҒжҜҸж¬ЎйғҪеҒҡDNSжҹҘиҜўгҖӮеҮ зҷҫдёӘиҝһжҺҘеҸҜиғҪеӨ„дәҺдёҚеҗҢзҡ„зҠ¶жҖҒпјҡжҹҘиҜўDNSпјҢиҝһжҺҘдё»жңәпјҢеҸ‘йҖҒиҜ·жұӮпјҢжҺҘеҸ—е“Қеә”гҖӮиҝҷдәӣеӣ зҙ дҪҝеҫ—зҲ¬иҷ«жҲҗдёәзі»з»ҹйҮҢдёҖдёӘеӨҚжқӮзҡ„жЁЎеқ—гҖӮе®ғз”ЁејӮжӯҘIOжқҘз®ЎзҗҶдәӢ件пјҢз”ЁдёҖдәӣйҳҹеҲ—жқҘз®ЎзҗҶйЎөйқўжҠ“еҸ–зҡ„зҠ¶жҖҒгҖӮ
дәӢе®һиҜҒжҳҺпјҢзҲ¬иҷ«иҝһжҺҘдәҶ50еӨҡдёҮдёӘжңҚеҠЎеҷЁпјҢдә§з”ҹдәҶеҮ еҚғдёҮжқЎж—Ҙеҝ—дҝЎжҒҜпјҢдјҡеёҰжқҘеӨ§йҮҸзҡ„з”өеӯҗйӮ®д»¶е’Ңз”өиҜқгҖӮеӣ дёәеҫҲеӨҡдәәеңЁзҪ‘дёҠпјҢ他们并дёҚзҹҘйҒ“зҲ¬иҷ«жҳҜд»Җд№ҲпјҢеӣ дёәиҝҷжҳҜ他们第дёҖж¬Ўи§ҒеҲ°гҖӮеҮ д№ҺжҜҸеӨ©пјҢжҲ‘们йғҪдјҡ收еҲ°иҝҷж ·зҡ„з”өеӯҗйӮ®д»¶пјҡвҖңе“ҮпјҢдҪ зңӢдәҶеҘҪеӨҡжҲ‘з«ҷдёҠзҡ„йЎөйқўпјҢдҪ и§үеҫ—жҖҺд№Ҳж ·пјҹвҖқд№ҹжңүеҫҲеӨҡдәә并дёҚзҹҘйҒ“зҲ¬иҷ«зҰҒз”ЁеҚҸи®®пјҲrobots exclusion protocolпјүпјҢ他们и®ӨдёәеҸҜд»ҘйҖҡиҝҮеңЁйЎөйқўдёҠеЈ°жҳҺвҖңжң¬йЎөйқўеҸ—зүҲжқғдҝқжҠӨпјҢжӢ’з»қзҙўеј•вҖқе°ұеҸҜд»ҘдҝқжҠӨйЎөйқўпјҢдёҚз”ЁиҜҙпјҢзҪ‘з»ңзҲ¬иҷ«еҫҲйҡҫзҗҶи§Јиҝҷж ·зҡ„иҜқгҖӮиҖҢдё”пјҢз”ұдәҺж¶үеҸҠеҲ°еӨ§йҮҸзҡ„ж•°жҚ®пјҢдёҖдәӣж„ҸжғідёҚеҲ°зҡ„дәӢжғ…жҖ»дјҡеҸ‘з”ҹгҖӮжҜ”еҰӮпјҢжҲ‘们зҡ„зі»з»ҹиҜ•еӣҫеҺ»жҠ“еҸ–дёҖдёӘеңЁзәҝжёёжҲҸгҖӮиҝҷеҜјиҮҙдәҶжёёжҲҸдёӯеҮәзҺ°еӨ§йҮҸзҡ„еһғеңҫж¶ҲжҒҜпјҒиҝҷдёӘй—®йўҳиў«иҜҒе®һжҳҜеҫҲе®№жҳ“и§ЈеҶізҡ„гҖӮдҪҶжҳҜеҫҖеҫҖжҲ‘们еңЁдёӢиҪҪдәҶеҮ еҚғдёҮдёӘйЎөйқўд№ӢеҗҺиҝҷдёӘй—®йўҳжүҚиў«еҸ‘зҺ°гҖӮеӣ дёәзҪ‘з»ңйЎөйқўе’ҢжңҚеҠЎеҷЁжҖ»жҳҜеңЁеҸҳеҢ–дёӯпјҢеңЁзҲ¬иҷ«жӯЈејҸиҝҗиЎҢеңЁеӨ§йғЁеҲҶзҡ„дә’иҒ”зҪ‘з«ҷзӮ№д№ӢеүҚжҳҜдёҚеҸҜиғҪиҝӣиЎҢжөӢиҜ•зҡ„гҖӮдёҚеҸҳзҡ„жҳҜпјҢжҖ»жңүдёҖдәӣеҘҮжҖӘзҡ„й”ҷиҜҜеҸӘдјҡеңЁдёҖдёӘйЎөйқўйҮҢйқўеҮәзҺ°пјҢ并且еҜјиҮҙзҲ¬иҷ«еҙ©жәғпјҢжҲ–иҖ…жӣҙеқҸпјҢеҜјиҮҙдёҚеҸҜйў„жөӢзҡ„жҲ–иҖ…й”ҷиҜҜзҡ„иЎҢдёәгҖӮйңҖиҰҒи®ҝй—®еӨ§йҮҸдә’иҒ”зҪ‘з«ҷзӮ№зҡ„зі»з»ҹйңҖиҰҒи®ҫи®Ўеҫ—еҫҲеҒҘ壮并且е°Ҹеҝғең°жөӢиҜ•гҖӮеӣ дёәеӨ§йҮҸеғҸзҲ¬иҷ«иҝҷж ·зҡ„зі»з»ҹжҢҒз»ӯеҜјиҮҙй—®йўҳпјҢжүҖд»ҘйңҖиҰҒеӨ§йҮҸзҡ„дәәеҠӣдё“й—Ёйҳ…иҜ»з”өеӯҗйӮ®д»¶пјҢеӨ„зҗҶж–°еҮәзҺ°йҒҮеҲ°зҡ„й—®йўҳгҖӮ
4.4 зҪ‘з«ҷзҙўеј•пјҲIndexing the Webпјү
и§ЈжһҗвҖ”вҖ”д»»дҪ•иў«и®ҫи®ЎжқҘи§Јжһҗж•ҙдёӘдә’иҒ”зҪ‘зҡ„и§ЈжһҗеҷЁйғҪеҝ…йЎ»еӨ„зҗҶеӨ§йҮҸеҸҜиғҪзҡ„й”ҷиҜҜгҖӮд»ҺHTMLж ҮзӯҫйҮҢйқўзҡ„й”ҷеҲ«еӯ—еҲ°дёҖдёӘж ҮзӯҫйҮҢйқўдёҠеҚғеӯ—иҠӮзҡ„0пјҢйқһASCIIеӯ—з¬ҰпјҢеөҢеҘ—дәҶеҮ зҷҫеұӮзҡ„HTMLж ҮзӯҫпјҢиҝҳжңүеӨ§йҮҸи¶…д№ҺдәәжғіиұЎзҡ„й”ҷиҜҜе’ҢвҖңеҲӣж„ҸвҖқгҖӮдёәдәҶиҫҫеҲ°жңҖеҝ«зҡ„йҖҹеәҰпјҢжҲ‘们没жңүдҪҝз”ЁYACCдә§з”ҹCFGпјҲcontext free grammaпјҢдёҠдёӢж–Үж— е…іж–Үжі•пјүи§ЈжһҗеҷЁпјҢиҖҢжҳҜз”Ёflexй…ҚеҗҲе®ғиҮӘе·ұзҡ„ж Ҳз”ҹжҲҗдәҶдёҖдёӘиҜҚжі•еҲҶжһҗеҷЁгҖӮејҖеҸ‘иҝҷж ·дёҖдёӘи§ЈжһҗеҷЁйңҖиҰҒеӨ§йҮҸзҡ„е·ҘдҪңжүҚиғҪдҝқиҜҒе®ғзҡ„йҖҹеәҰе’ҢеҒҘеЈ®гҖӮ
дёәж–ҮжЎЈе»әз«ӢжЎ¶зҙўеј•вҖ”вҖ”жҜҸдёҖдёӘж–ҮжЎЈи§ЈжһҗиҝҮеҗҺпјҢзј–з Ғеӯҳе…ҘжЎ¶йҮҢйқўгҖӮжҜҸдёҖдёӘеҚ•иҜҚиў«еҶ…еӯҳйҮҢзҡ„е“ҲеёҢиЎЁвҖ”вҖ”иҜҚе…ёиҪ¬еҢ–жҲҗдёҖдёӘwordIDгҖӮиҜҚе…ёе“ҲеёҢиЎЁж–°еҠ зҡ„еҶ…е®№йғҪиў«и®°еҪ•еңЁдёҖдёӘж–Ү件йҮҢгҖӮеҚ•иҜҚеңЁиў«иҪ¬еҢ–жҲҗжҲ‘wordIDзҡ„ж—¶еҖҷпјҢ他们еңЁеҪ“еүҚж–ҮжЎЈдёӯзҡ„еҮәзҺ°дјҡиў«зҝ»иҜ‘жҲҗе‘ҪдёӯеҲ—иЎЁпјҢ并еҶҷе…ҘжӯЈжҺ’жЎ¶(forward barrels)дёӯгҖӮе»әз«Ӣзҙўеј•йҳ¶ж®өзҡ„并иЎҢж“ҚдҪңдё»иҰҒзҡ„еӣ°йҡҫеңЁдәҺиҜҚе…ёйңҖиҰҒе…ұдә«гҖӮжҲ‘们并没жңүе…ұдә«ж•ҙдёӘиҜҚе…ёпјҢиҖҢжҳҜеңЁеҶ…еӯҳйҮҢдҝқеӯҳдёҖд»Ҫеҹәжң¬иҜҚе…ёпјҢеӣәе®ҡзҡ„1еҚғ4зҷҫдёҮдёӘеҚ•иҜҚпјҢеӨҡдҪҷзҡ„иҜҚеҶҷе…ҘдёҖдёӘж—Ҙеҝ—ж–Ү件гҖӮиҝҷж ·пјҢеӨҡдёӘзҙўеј•еҷЁе°ұеҸҜд»ҘеҗҢж—¶иҝҗиЎҢпјҢжңҖеҗҺз”ұдёҖдёӘзҙўеј•еҷЁжқҘеӨ„зҗҶиҝҷдёӘи®°еҪ•зқҖеӨҡдҪҷеҚ•иҜҚзҡ„е°Ҹж—Ҙеҝ—ж–Ү件гҖӮ
жҺ’еәҸвҖ”вҖ”дёәдәҶдә§з”ҹеҖ’жҺ’зҙўеј•пјҢжҺ’еәҸеҷЁеҸ–еҮәеҗ„дёӘжӯЈжҺ’зҡ„жЎ¶пјҢ然еҗҺж №жҚ®wordIDжҺ’еәҸжқҘдә§з”ҹдёҖдёӘж Үйўҳе’Ңй”ҡе‘Ҫдёӯзҡ„еҖ’жҺ’жЎ¶пјҢе’ҢдёҖдёӘе…Ёж–Үзҡ„еҖ’жҺ’жЎ¶гҖӮжҜҸж¬ЎеӨ„зҗҶдёҖдёӘжЎ¶пјҢжүҖд»ҘйңҖиҰҒзҡ„жҡӮеӯҳз©әй—ҙеҫҲе°‘гҖӮиҖҢдё”пјҢжҲ‘们з®ҖеҚ•ең°йҖҡиҝҮз”Ёе°ҪеҸҜиғҪеӨҡзҡ„жңәеҷЁиҝҗиЎҢеӨҡдёӘжҺ’еәҸеҷЁеҒҡеҲ°жҺ’еәҸзҡ„并иЎҢеҢ–пјҢдёҚеҗҢзҡ„жҺ’еәҸеҷЁеҸҜд»ҘеҗҢж—¶еӨ„зҗҶдёҚеҗҢзҡ„жЎ¶гҖӮеӣ дёә桶并дёҚиғҪе…ЁйғЁж”ҫеңЁдё»еӯҳйҮҢйқўпјҢжҺ’еәҸеҷЁдјҡж №жҚ®wordIDе’ҢdocIDе°Ҷе®ғ们иҝӣдёҖжӯҘеҲҶеүІжҲҗеҸҜд»Ҙж”ҫеңЁеҶ…еӯҳйҮҢйқўзҡ„жЎ¶(basket)гҖӮжҺҘзқҖпјҢжҺ’еәҸеҷЁе°ҶжҜҸдёӘжЎ¶иҪҪе…ҘеҶ…еӯҳпјҢжҺ’еҘҪеәҸпјҢжҠҠеҶ…е®№еҶҷе…Ҙзҹӯзҡ„еҖ’жҺ’жЎ¶е’Ңе®Ңж•ҙзҡ„еҖ’жҺ’жЎ¶гҖӮ
4.5 жҗңзҙўпјҲSearchingпјү
жҗңзҙўзҡ„зӣ®ж ҮжҳҜй«ҳж•Ҳең°иҝ”еӣһй«ҳиҙЁйҮҸзҡ„з»“жһңгҖӮеҫҲеӨҡеӨ§еһӢзҡ„е•Ҷдёҡжҗңзҙўеј•ж“ҺеңЁж•ҲзҺҮж–№йқўзңӢиө·жқҘйғҪжңүеҫҲеӨ§зҡ„иҝӣжӯҘгҖӮжүҖд»ҘжҲ‘们жӣҙдё“жіЁдәҺжҗңзҙўз»“жһңзҡ„иҙЁйҮҸпјҢдҪҶжҳҜжҲ‘们зӣёдҝЎжҲ‘们зҡ„и§ЈеҶіж–№жЎҲеҸӘиҰҒиҠұдёҖзӮ№зІҫеҠӣе°ұеҸҜд»ҘеҫҲеҘҪзҡ„еә”з”ЁеҲ°е•Ҷдёҡзҡ„ж•°жҚ®дёҠгҖӮGoogleзҡ„жҹҘиҜўиҜ„дј°жөҒзЁӢеҰӮеӣҫ4гҖӮ
дёәдәҶйҷҗеҲ¶е“Қеә”ж—¶й—ҙпјҢдёҖж—ҰжҹҗдёӘж•°йҮҸ(зҺ°еңЁжҳҜ40,000)зҡ„еҢ№й…Қж–ҮжЎЈиў«жүҫеҲ°пјҢжҗңзҙўеҷЁиҮӘеҠЁи·іеҲ°еӣҫ4дёӯзҡ„第8жӯҘгҖӮиҝҷж„Ҹе‘ізқҖжңүеҸҜиғҪиҝ”еӣһж¬Ўдјҳзҡ„з»“жһңгҖӮжҲ‘们зҺ°еңЁеңЁз ”究新зҡ„ж–№жі•жқҘи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮеңЁиҝҮеҺ»пјҢжҲ‘д»¬ж №жҚ®PageRankеҖјжҺ’еәҸпјҢжңүиҫғеҘҪзҡ„ж•ҲжһңгҖӮ
и§ЈжһҗжҹҘиҜўпјҲQueryпјүгҖӮ
жҠҠеҚ•иҜҚиҪ¬еҢ–жҲҗwordIDгҖӮ
д»ҺжҜҸдёӘеҚ•иҜҚзҡ„зҹӯжЎ¶ж–ҮжЎЈеҲ—иЎЁејҖе§ӢжҹҘжүҫгҖӮ
жү«жҸҸж–ҮжЎЈеҲ—иЎЁзӣҙеҲ°жңүдёҖдёӘж–ҮжЎЈеҢ№й…ҚдәҶжүҖжңүзҡ„жҗңзҙўиҜҚиҜӯгҖӮ
и®Ўз®—иҝҷдёӘж–ҮжЎЈеҜ№еә”дәҺжҹҘиҜўзҡ„иҜ„еҲҶгҖӮ
еҰӮжһңжҲ‘们еҲ°иҫҫзҹӯжЎ¶зҡ„ж–ҮжЎЈеҲ—иЎЁз»“е°ҫпјҢд»ҺжҜҸдёӘеҚ•иҜҚзҡ„е…ЁжЎ¶(full barrel)ж–ҮжЎЈеҲ—иЎЁејҖе§ӢжҹҘжүҫпјҢи·іеҲ°з¬¬4жӯҘгҖӮ
еҰӮжһңжҲ‘们没жңүеҲ°иҫҫд»»дҪ•ж–ҮжЎЈеҲ—иЎЁзҡ„з»“е°ҫпјҢи·іеҲ°з¬¬4жӯҘгҖӮ
ж №жҚ®иҜ„еҲҶеҜ№еҢ№й…Қзҡ„ж–ҮжЎЈжҺ’еәҸпјҢ然еҗҺиҝ”еӣһиҜ„еҲҶжңҖй«ҳзҡ„kдёӘгҖӮ
еӣҫ4 GoogleжҹҘиҜўиҜ„дј°
4.5.1 иҜ„еҲҶзі»з»ҹпјҲThe Ranking Systemпјү
GoogleжҜ”е…ёеһӢзҡ„жҗңзҙўеј•ж“Һз»ҙжҠӨдәҶж №еӨҡзҡ„webж–ҮжЎЈзҡ„дҝЎжҒҜгҖӮжҜҸдёҖдёӘе‘ҪдёӯеҲ—иЎЁпјҲhitlistпјүеҢ…еҗ«дәҶдҪҚзҪ®пјҢеӯ—дҪ“е’ҢеӨ§е°ҸеҶҷдҝЎжҒҜгҖӮиҖҢдё”пјҢжҲ‘们综еҗҲиҖғиҷ‘дәҶй”ҡж–Үжң¬е‘Ҫдёӯе’ҢйЎөйқўзҡ„PageRankеҖјгҖӮжҠҠжүҖжңүзҡ„дҝЎжҒҜз»јеҗҲжҲҗдёҖдёӘиҜ„еҲҶжҳҜеҫҲеӣ°йҡҫзҡ„гҖӮжҲ‘们и®ҫи®ЎдәҶиҜ„еҲҶеҮҪж•°дҝқиҜҒжІЎжңүдёҖдёӘеӣ зҙ жңүеӨӘеӨ§зҡ„еҪұе“ҚгҖӮйҰ–е…ҲпјҢиҖғиҷ‘з®ҖеҚ•зҡ„жғ…еҶөвҖ”вҖ”дёҖдёӘеҚ•иҜҚзҡ„жҹҘиҜўгҖӮдёәдәҶеҜ№дёҖдёӘеҚ•иҜҚзҡ„жҹҘиҜўи®Ўз®—ж–ҮжЎЈзҡ„еҲҶеҖјпјҢGoogleйҰ–е…ҲдёәиҝҷдёӘеҚ•иҜҚжҹҘзңӢиҝҷдёӘж–ҮжЎЈзҡ„е‘ҪдёӯеҲ—иЎЁгҖӮGoogleе°Ҷе‘ҪдёӯеҲҶдёәдёҚеҗҢзұ»еһӢпјҲж ҮйўҳпјҢй”ҡпјҢURLпјҢжҷ®йҖҡж–Үжң¬еӨ§еӯ—дҪ“пјҢжҷ®йҖҡж–Үжң¬е°Ҹеӯ—дҪ“пјҢвҖҰвҖҰпјүпјҢжҜҸдёҖз§Қзұ»еһӢйғҪжңүиҮӘе·ұзҡ„зұ»еһӢжқғйҮҚеҖјпјҲtype-weightпјүгҖӮзұ»еһӢжқғйҮҚеҖјжһ„жҲҗдёҖдёӘз”ұзұ»еһӢеҜ»еқҖпјҲindexedпјүзҡ„еҗ‘йҮҸгҖӮGoogleж•°еҮәе‘ҪдёӯеҲ—иЎЁдёӯжҜҸз§Қзұ»еһӢе‘Ҫдёӯзҡ„ж•°йҮҸгҖӮжҜҸдёӘж•°йҮҸиҪ¬еҢ–жҲҗдёҖдёӘж•°йҮҸжқғйҮҚпјҲcount-weightпјүгҖӮж•°йҮҸжқғйҮҚејҖе§ӢйҡҸзқҖж•°йҮҸзәҝжҖ§еўһй•ҝпјҢдҪҶжҳҜеҫҲеҝ«еҒңжӯўеўһй•ҝпјҢд»ҘдҝқиҜҒеҚ•иҜҚе‘Ҫдёӯж•°еӨҡдәҺжҹҗдёӘж•°йҮҸд№ӢеҗҺеҜ№жқғйҮҚдёҚеҶҚжңүеҪұе“ҚгҖӮжҲ‘们йҖҡиҝҮж•°йҮҸжқғйҮҚеҗ‘йҮҸе’Ңзұ»еһӢжқғйҮҚеҗ‘йҮҸзҡ„зӮ№д№ҳдёәдёҖдёӘж–ҮжЎЈз®—еҮәдёҖдёӘIRеҲҶж•°гҖӮжңҖеҗҺиҝҷдёӘIRеҲҶж•°дёҺPageRankз»јеҗҲдә§з”ҹиҝҷдёӘж–ҮжЎЈжңҖз»Ҳзҡ„иҜ„еҲҶгҖӮ
еҜ№дәҺдёҖдёӘеӨҡиҜҚжҗңзҙўпјҢжғ…еҶөиҰҒжӣҙеӨҚжқӮгҖӮзҺ°еңЁпјҢеӨҡдёӘе‘ҪдёӯеҲ—иЎЁеҝ…йЎ»дёҖж¬Ўжү«жҸҸе®ҢпјҢиҝҷж ·дёҖдёӘж–ҮжЎЈдёӯиҫғиҝ‘зҡ„е‘ҪдёӯжүҚиғҪжҜ”зӣёи·қиҫғиҝңзҡ„е‘Ҫдёӯжңүжӣҙй«ҳзҡ„иҜ„еҲҶгҖӮеӨҡдёӘе‘ҪдёӯеҲ—иЎЁйҮҢзҡ„е‘Ҫдёӯз»“еҗҲиө·жқҘжүҚиғҪеҢ№й…ҚеҮәзӣёйӮ»зҡ„е‘ҪдёӯгҖӮеҜ№жҜҸдёҖдёӘе‘Ҫдёӯзҡ„еҢ№й…ҚйӣҶ(matched set)пјҢдјҡи®Ўз®—еҮәдёҖдёӘжҺҘиҝ‘еәҰгҖӮжҺҘиҝ‘еәҰжҳҜеҹәдәҺдёӨдёӘе‘ҪдёӯеңЁж–ҮжЎЈпјҲжҲ–й”ҡж–Үжң¬пјүдёӯзӣёйҡ”еӨҡиҝңи®Ўз®—зҡ„пјҢдҪҶжҳҜиў«еҲҶдёә10дёӘзӯүзә§д»ҺзҹӯиҜӯеҢ№й…ҚеҲ°вҖңдёҖзӮ№йғҪдёҚиҝ‘вҖқгҖӮдёҚе…үиҰҒдёәжҜҸдёҖз§Қзұ»еһӢзҡ„е‘Ҫдёӯи®Ўж•°пјҢиҝҳиҰҒдёәжҜҸдёҖз§Қзұ»еһӢе’ҢжҺҘиҝ‘еәҰйғҪи®Ўж•°гҖӮжҜҸдёҖдёӘзұ»еһӢе’ҢжҺҘиҝ‘еәҰзҡ„з»„жңүдёҖдёӘзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚпјҲtype-prox-weightпјүгҖӮж•°йҮҸиў«иҪ¬еҢ–жҲҗж•°йҮҸжқғйҮҚгҖӮжҲ‘们йҖҡиҝҮеҜ№ж•°йҮҸжқғйҮҚе’Ңзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚеҒҡзӮ№д№ҳи®Ўз®—еҮәIRеҲҶеҖјгҖӮжүҖжңүиҝҷдәӣж•°еӯ—е’Ңзҹ©йҳөйғҪдјҡеңЁзү№ж®Ҡзҡ„и°ғиҜ•жЁЎејҸдёӢдёҺжҗңзҙўз»“жһңдёҖиө·жҳҫзӨәеҮәжқҘгҖӮиҝҷдәӣжҳҫзӨәз»“жһңеңЁејҖеҸ‘иҜ„еҲҶзі»з»ҹзҡ„ж—¶еҖҷеҫҲжңүеё®еҠ©гҖӮ
4.5.2 еҸҚйҰҲпјҲFeedbackпјү
иҜ„еҲҶеҮҪж•°жңүеҫҲеӨҡеҸӮж•°жҜ”еҰӮзұ»еһӢжқғйҮҚе’Ңзұ»еһӢ-жҺҘиҝ‘еәҰжқғйҮҚгҖӮжүҫеҮәиҝҷдәӣеҸӮж•°зҡ„жқғйҮҚеҖјз®Җзӣҙе°ұи·ҹеҰ–жңҜдёҖж ·гҖӮдёәдәҶи°ғж•ҙиҝҷдәӣеҸӮж•°пјҢжҲ‘们еңЁжҗңзҙўеј•ж“ҺйҮҢжңүдёҖдёӘз”ЁжҲ·еҸҚйҰҲжңәеҲ¶гҖӮдёҖдёӘиў«дҝЎд»»зҡ„з”ЁжҲ·еҸҜд»ҘйҖүжӢ©жҖ§ең°иҜ„д»·жүҖжңүзҡ„иҝ”еӣһз»“жһңгҖӮиҝҷдёӘеҸҚйҰҲиў«и®°еҪ•дёӢжқҘгҖӮ然еҗҺеңЁжҲ‘们改еҸҳиҜ„еҲҶзі»з»ҹзҡ„ж—¶еҖҷпјҢжҲ‘们иғҪзңӢеҲ°дҝ®ж”№еҜ№д№ӢеүҚиҜ„д»·иҝҮзҡ„жҗңзҙўз»“жһңзҡ„еҪұе“ҚгҖӮе°Ҫз®Ўиҝҷж ·е№¶дёҚе®ҢзҫҺпјҢдҪҶжҳҜиҝҷд№ҹз»ҷжҲ‘们дёҖдәӣж”№еҸҳиҜ„еҲҶеҮҪж•°жқҘеҪұе“Қжҗңзҙўз»“жһңзҡ„жғіжі•гҖӮ
5 з»“жһңдёҺиЎЁзҺ°
иЎЎйҮҸдёҖдёӘжҗңзҙўеј•ж“ҺжңҖйҮҚиҰҒзҡ„ж ҮеҮҶжҳҜе…¶жҗңзҙўз»“жһңзҡ„иҙЁйҮҸгҖӮиҷҪ然еҰӮдҪ•еҒҡдёҖдёӘе®Ңж•ҙзҡ„з”ЁжҲ·иҜ„дј°и¶…и¶ҠдәҶжң¬ж–Үзҡ„иҢғеӣҙпјҢдҪҶжҳҜжҲ‘们еңЁGoogleиә«дёҠеҫ—еҲ°зҡ„з»ҸйӘҢпјҢиЎЁжҳҺе®ғжҸҗдҫӣз»“жһңпјҢжҜ”дё»иҰҒе•Ҷз”Ёжҗңзҙўеј•ж“ҺеҜ№з»қеӨ§еӨҡж•°жҗңзҙўжҸҗдҫӣзҡ„з»“жһңжӣҙеҘҪгҖӮеӣҫиЎЁ4 иЎЁзӨәзҡ„ GoogleеҜ№дәҺжҗңзҙўвҖңжҜ”е°”.е…Ӣжһ—йЎҝвҖқзҡ„з»“жһңпјҢдҪңдёәдёҖдёӘдҫӢеӯҗеҸҜд»ҘиҜҙжҳҺпјҢеҜ№PageRank, anchor text пјҲе…ій”®иҜҚпјү,е’ҢproximityпјҲзӣёдјјеәҰпјүзҡ„дҪҝз”ЁгҖӮиҝҷж ·зҡ„жҗңзҙўз»“жһңжҳҫзӨәдәҶGoogleзҡ„зү№иүІгҖӮжҗңзҙўз»“жһңиў«жңҚеҠЎеҷЁдёІиҒ”еңЁдёҖиө·гҖӮиҝҷж ·зҡ„ж–№жі•еҪ“еңЁйңҖиҰҒеҜ№з»“жһңйӣҶзӯӣйҖүж—¶йқһеёёжңүз”ЁгҖӮеҫҲеӨ§ж•°йҮҸзҡ„з»“жһңдјҡжқҘиҮӘеҹҹеҗҚwhitehouse.govпјҢжңүзҗҶз”ұзӣёдҝЎиҝҷдёӘжқҘжәҗеҗ«жңүжң¬ж¬ЎиҜҘжҗңзҙўдёӯиў«жңҹжңӣжүҫеҲ°зҡ„з»“жһңгҖӮеҪ“еүҚпјҢз»қеӨ§еӨҡж•°дё»иҰҒзҡ„е•Ҷз”Ёжҗңзҙўеј•ж“ҺдёҚдјҡиҝ”еӣһд»»дҪ•жқҘиҮӘwhitehouse.govзҡ„з»“жһңпјҢжӣҙдёҚз”ЁиҜҙжӯЈзЎ®зҡ„з»“жһңгҖӮжіЁж„ҸпјҢ第дёҖдёӘжҗңзҙўеҲ°зҡ„иҝһжҺҘжІЎжңүж ҮйўҳпјҢжҳҜеӣ дёәе®ғдёҚжҳҜжҠ“еҸ–еҫ—з»“жһңпјҢиҖҢжҳҜGoogle еҹәдәҺanchor text еҶіе®ҡиҝҷдёӘз»“жһңжҳҜжҹҘиҜўжүҖжңҹжңӣеҫ—еҲ°зҡ„еҘҪз»“жһңгҖӮеҗҢж ·зҡ„пјҢ第15еҸ·з»“жһңжҳҜдёҖдёӘз”өеӯҗйӮ®д»¶ең°еқҖпјҢеҪ“然иҝҷд№ҹжҳҜеҹәдәҺanchor textзҡ„з»“жһңпјҢиҖҢйқһеҸҜжҠ“еҸ–еҫ—з»“жһңгҖӮ
жүҖжңүз»“жһңйғҪжҳҜеҗҲзҗҶзҡ„й«ҳиҙЁйҮҸйЎөйқўпјҢиҖҢдё”жңҖеҗҺжЈҖжҹҘпјҢжІЎжңүеқҸиҝһжҺҘгҖӮиҝҷдё»иҰҒеҪ’еҠҹдәҺ他们жңүеҫҲй«ҳзҡ„PageRankгҖӮPageRankзҡ„зҷҫеҲҶжҜ”дҪҝз”ЁзәўиүІжқЎеҪўеӣҫиЎЁзӨәгҖӮжңҖеҗҺпјҢиҝҷйҮҢзҡ„з»“жһңдёӯпјҢжІЎжңүеҸӘжңүBillжІЎжңүClinton жҲ–еҸӘжңү Clinton жІЎжңүBill зҡ„пјҢиҝҷжҳҜеӣ дёәжҲ‘们еңЁе…ій”®иҜҚеҮәзҺ°ж—¶дҪҝз”ЁдәҶйқһеёёйҮҚиҰҒзҡ„proximityгҖӮеҪ“然еҜ№дёҖдёӘе®һйҷ…зҡ„еҜ№жҗңзҙўеј•ж“Һзҡ„иҙЁйҮҸжөӢиҜ•еә”иҜҘеҢ…жӢ¬е№ҝжіӣзҡ„еҜ№з”ЁжҲ·з ”究жҲ–иҖ…еҜ№жҗңзҙўз»“жһңзҡ„еҲҶжһҗпјҢдҪҶжҳҜжҲ‘们没жңүж—¶й—ҙеҒҡд»ҘдёҠжһҗгҖӮдҪҶжҳҜжҲ‘们йӮҖиҜ·иҜ»иҖ…еңЁ http://google.stanford.edu/flp иҮӘе·ұжөӢиҜ•GoogleгҖӮ
5.1 еӯҳеӮЁйңҖжұӮ
йҷӨжҗңзҙўиҙЁйҮҸеӨ–пјҢGooogleиў«и®ҫи®ЎдёәиғҪеӨҹж¶ҲеҢ–дә’иҒ”зҪ‘规模дёҚж–ӯеўһй•ҝеёҰжқҘзҡ„ж•ҲиғҪй—®йўҳгҖӮдёҖж–№йқўпјҢдҪҝз”Ёй«ҳж•ҲеӯҳеӮЁгҖӮиЎЁдёҖжҳҜеҜ№Googleзҡ„з»ҹи®ЎдёҺеӯҳеӮЁйңҖжұӮзҡ„иҜҰз»ҶеҲҶзұ»пјҢз”ұдәҺеҺӢзј©еҗҺзҡ„еӯҳеӮЁдҪ“з§Ҝдёә53GBпјҢдёәжәҗж•°жҚ®зҡ„дёүеҲҶд№ӢдёҖеӨҡдёҖзӮ№гҖӮе°ұеҪ“еүҚзҡ„зЎ¬зӣҳд»·ж јжқҘиҜҙеҸҜд»Ҙдёәжңүз”Ёиө„жәҗжҸҗдҫӣе»үд»·зҡ„зӣёе…іеӯҳеӮЁи®ҫеӨҮгҖӮжӣҙйҮҚиҰҒзҡ„жҳҜпјҢжҗңзҙўеј•ж“ҺдҪҝз”Ёзҡ„жүҖжңүж•°жҚ®зҡ„жҖ»еҗҲйңҖиҰҒзӣёеә”зҡ„еӯҳеӮЁеӨ§зәҰдёә55GBгҖӮжӯӨеӨ–пјҢеӨ§еӨҡж•°жҹҘиҜўиғҪиў«иҰҒжұӮе……еҲҶдҪҝз”ЁзҹӯеҸҚеҗ‘зҙўеј• [short inverted index]пјҢеңЁжӣҙеҘҪзҡ„зј–з ҒдёҺеҺӢзј©ж–ҮжЎЈзҙўеј•еҗҺпјҢдёҖдёӘй«ҳиҙЁйҮҸзҡ„зҪ‘з»ңжҗңзҙўеј•ж“ҺеҸҜиғҪеҸӘйңҖиҰҒдёҖеҸ°жңү7GBеӯҳеӮЁз©әй—ҙзҡ„ж–°з”өи„‘гҖӮ
5.2 зі»з»ҹжҖ§иғҪ
иҝҷеҜ№жҗңзҙўеј•ж“Һзҡ„жҠ“еҸ–дёҺзҙўеј•жқҘиҜҙеҫҲйҮҚиҰҒгҖӮиҝҷж ·дҝЎжҒҜиў«иҪ¬еҢ–дёәж•°жҚ®зҡ„йҖҹеәҰд»ҘеҸҠзі»з»ҹдё»иҰҒйғЁеҲҶж”№еҸҳеҗҺиў«жөӢиҜ•зҡ„йҖҹеәҰйғҪзӣёеҜ№жӣҙеҝ«гҖӮе°ұGoogleжқҘиҜҙпјҢдё»иҰҒж“ҚдҪңеҢ…жӢ¬пјҡжҠ“еҸ–пјҢзҙўеј•е’ҢжҺ’еәҸгҖӮдёҖж—ҰзЎ¬зӣҳиў«еЎ«ж»ЎгҖҒжҲ–е‘ҪеҗҚжңҚеҠЎеҷЁеҙ©жәғпјҢжҲ–иҖ…е…¶е®ғй—®йўҳеҜјиҮҙзі»з»ҹеҒңжӯўпјҢйғҪеҫҲйҡҫеәҰйҮҸжҠ“еҸ–жүҖйңҖиҰҒеҢ–иҙ№зҡ„ж—¶й—ҙгҖӮе…ЁйғЁиҠұиҙ№еңЁдёӢиҪҪ2еҚғ6зҷҫдёҮдёӘйЎөйқў[еҢ…жӢ¬й”ҷиҜҜйЎөйқў]зҡ„ж—¶й—ҙеӨ§жҰӮжҳҜ9еӨ©гҖӮдҪҶжҳҜеҰӮжһңзі»з»ҹиҝҗиЎҢжӣҙдёәжөҒз•…пјҢиҝҷдёӘиҝҮзЁӢиҝҳеҸҜд»Ҙжӣҙеҝ«пјҢжңҖеҗҺзҡ„1еҚғ1зҷҫдёӘйЎөйқўеҸӘдҪҝз”ЁдәҶ63дёӘе°Ҹж—¶пјҢе№іеқҮ4зҷҫдёҮжҜҸеӨ©пјҢжҜҸз§’48.5йЎөгҖӮзҙўеј•зҡ„иҝҗиЎҢйҖҹеәҰеҝ«дәҺжҠ“еҸ–йҖҹеәҰзҡ„йҮҚиҰҒеҺҹеӣ жҳҜжҲ‘们иҠұиҙ№дәҶи¶іеӨҹзҡ„ж—¶й—ҙжқҘдјҳеҢ–зҙўеј•зЁӢеәҸпјҢдҪҝе®ғдёҚиҰҒжҲҗдёә瓶йўҲгҖӮдјҳеҢ–еҢ…жӢ¬еҜ№жң¬ең°зЎ¬зӣҳдёҠзҡ„ж–ҮжЎЈзҡ„зҙўеј•иҝӣиЎҢеӨ§и§„жЁЎзҡ„еҚҮзә§е’ҢжӣҝжҚўе…ій”®зҡ„ж•°жҚ®з»“жһ„гҖӮзҙўеј•зҡ„йҖҹеәҰиҫҫеҲ°еӨ§жҰӮ54йЎөжҜҸз§’гҖӮжҺ’еәҸеҸҜд»Ҙе®Ңе…Ёе№іиЎҢдҪңдёҡпјҢдҪҝз”ЁеӣӣеҸ°жңәеҷЁпјҢж•ҙдёӘеӨ„зҗҶж—¶й—ҙиҠұиҙ№иҝ‘24дёӘе°Ҹж—¶гҖӮ
5.3 жҗңзҙўжҖ§иғҪ
жҸҗй«ҳжҗңзҙўжҖ§иғҪ并дёҚжҳҜжң¬ж¬ЎжҲ‘д»¬з ”з©¶зҡ„йҮҚзӮ№гҖӮеҪ“еүҚзүҲжң¬зҡ„Googleиҝ”еӣһеӨҡж•°жҹҘиҜўз»“жһңзҡ„ж—¶й—ҙжҳҜ1еҲ°10з§’гҖӮиҝҷдёӘж—¶й—ҙдё»иҰҒеҸ—еҲ°зЎ¬зӣҳIOд»ҘеҸҠNFS[зҪ‘з»ңж–Ү件系з»ҹпјҢеҪ“зЎ¬зӣҳе®үзҪ®еҲ°и®ёеӨҡжңәеҷЁдёҠж—¶дҪҝз”Ё] зҡ„йҷҗеҲ¶гҖӮиҝӣдёҖжӯҘиҜҙпјҢGoogleжІЎжңүеҒҡд»»дҪ•дјҳеҢ–пјҢдҫӢеҰӮжҹҘиҜўзј“еҶІеҢәпјҢеёёз”ЁиҜҚжұҮеӯҗзҙўеј•пјҢе’Ңе…¶е®ғеёёз”Ёзҡ„дјҳеҢ–жҠҖжңҜгҖӮжҲ‘们еҖҫеҗ‘дәҺйҖҡиҝҮеҲҶеёғејҸпјҢ硬件пјҢиҪҜ件пјҢе’Ңз®—жі•зҡ„ж”№иҝӣжқҘжҸҗй«ҳGoogleзҡ„йҖҹеәҰгҖӮжҲ‘们зҡ„зӣ®ж ҮжҳҜжҜҸз§’иғҪеӨ„зҗҶеҮ зҷҫдёӘиҜ·жұӮгҖӮиЎЁ2жңүеҮ дёӘзҺ°еңЁзүҲжң¬Googleе“Қеә”жҹҘиҜўж—¶й—ҙзҡ„дҫӢеӯҗгҖӮе®ғ们иҜҙжҳҺIOзј“еҶІеҢәеҜ№еҶҚж¬ЎжҗңзҙўйҖҹеәҰзҡ„еҪұе“ҚгҖӮ
еҸҰеӨ–дёҖзҜҮеҸӮиҖғиҜ‘ж–Үпјҡhttp://blog.csdn.net/fxy_2002/archive/2004/12/23/226604.aspx
еҲҶдә«еҲ°пјҡ


- 2010-12-01 20:38
- жөҸи§Ҳ 1152
- иҜ„и®ә(0)
- еҲҶзұ»:дә’иҒ”зҪ‘
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

зӣёе…іжҺЁиҚҗ
еӨ§и§„жЁЎи¶…ж–Үжң¬зҪ‘з»ңжҗңзҙўеј•ж“Һеү–жһҗ.pdf
ж–Үжң¬еҗ‘йҮҸжҗңзҙўдёҺGPTз»“еҗҲпјҡжһ„е»әй«ҳж•ҲдёӘдәәжҗңзҙўеј•ж“Һзҡ„е®һи·өдёҺеҲҶжһҗ
жҗңзҙўеј•ж“ҺеҲҶжһҗдёҺи®ҫи®Ў - зҪ‘з»ңе°ҸиҜҙжҗңзҙў еҚҸеҗҢиҝҮж»Ө жҗңзҙўеј•ж“ҺеҲҶжһҗдёҺи®ҫи®Ў - зҪ‘з»ңе°ҸиҜҙжҗңзҙў еҚҸеҗҢиҝҮж»Ө Python зҲ¬иҷ« Web жҗңзҙўзӣёдјје°ҸиҜҙпјҢжҗңзҙўзӣ®ж Үзұ»еһӢе°ҸиҜҙпјҢдёӘдәәжҺЁиҚҗжҰңеҚ•
иЎҢдёҡеҲҶзұ»-и®ҫеӨҮиЈ…зҪ®-еҹәдәҺHadoopзҡ„еӨ§и§„жЁЎзӨҫдәӨзҪ‘з»ңеҲҶжһҗж–№жі•еҸҠе…¶еҲҶжһҗе№іеҸ°.zip
02-жҗңзҙўеј•ж“ҺеҹәзЎҖпјҲе…ұ15йЎөпјү 03-зҪ‘з»ңзҲ¬иҷ«пјҲе…ұ27йЎөпјү 04-жӯЈеҲҷиЎЁиҫҫејҸпјҲе…ұ13йЎөпјү 05-HtmlAgilityPackпјҲе…ұ17йЎөпјү 06-жӯЈж–ҮжҸҗеҸ–пјҲе…ұ12йЎөпјү 07-жҸҗеҸ–ж–Ү件пјҲе…ұ14йЎөпјү 08-ж–Үжң¬жҺ’йҮҚпјҲе…ұ28йЎөпјү 09-жҸҗеҸ–е…ій”®иҜҚпјҲе…ұ16йЎөпјү 10-жӢјеҶҷ...
дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 03-зҪ‘з»ңзҲ¬иҷ«пјҲе…ұ27йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 04-жӯЈеҲҷиЎЁиҫҫејҸпјҲе…ұ13йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 05-...
дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 03-зҪ‘з»ңзҲ¬иҷ«пјҲе…ұ27йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 04-жӯЈеҲҷиЎЁиҫҫејҸпјҲе…ұ13йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 05-...
жҗңзҙўеј•ж“ҺдёӯзҪ‘з»ңзҲ¬иҷ«зҡ„з ”з©¶ и®әж–Ү жӯҰжұүзҗҶе·ҘеӨ§еӯҰзЎ•еЈ«еӯҰдҪҚи®әж–Ү 第1з« еј•иЁҖ 1.1йҖүйўҳиғҢжҷҜ дәәзұ»зӨҫдјҡзҡ„еҸ‘еұ•зҰ»дёҚејҖзҹҘиҜҶзҡ„иҺ·еҸ–дёҺеҸ‘зҺ°пјҢиҝӣе…Ҙдә’иҒ”зҪ‘ж—¶д»Јд»ҘеҗҺпјҢдҝЎжҒҜеҮәзҺ° дәҶйЈһйҖҹең°еўһй•ҝпјҢеҜ№дәҺзҪ‘з»ңдёҠдёҚж–ӯж¶ҢзҺ°зҡ„еҗ„з§ҚдҝЎжҒҜпјҢдәә们зҡ„жҺҘеҸ—...
з”өдҝЎи®ҫеӨҮ-дёҖз§Қйқўеҗ‘еӨ§и§„жЁЎеҠЁжҖҒзҹӯж–Үжң¬зҡ„иҒҡзұ»дҝЎжҒҜжј”еҢ–еҲҶжһҗж–№жі•.zip
жҗңзҙўеј•ж“ҺжЈҖзҙўз»“жһңзҡ„ж–ҮжЎЈеҲ—иЎЁйҖҡеёёиҝҮдәҺеәһеӨ§пјҢз»ҷз”ЁжҲ·йҖҗдёӘжөҸи§ҲеҜ»жүҫзӣёе…ізҡ„з»“жһңеёҰжқҘжһҒеӨ§дёҚдҫҝгҖӮдәҺжҳҜеңЁеҪ“еүҚжҗңзҙўеј•ж“Һзҡ„е·ҘдҪңжңәеҲ¶еҹәзЎҖд№ӢдёҠпјҢжң¬ж–ҮжҸҗеҮәеңЁз”ЁжҲ·жҺҘеҸЈдёҺжЈҖзҙўеҷЁд№Ӣй—ҙжҺҘе…Ҙж–Үжң¬еҲҶзұ»еҷЁпјҢз”ұе®ғеҜ№жЈҖзҙўз»“жһңиҮӘеҠЁең°иҝӣиЎҢиҒ”жңәеҲҶзұ»пјҢ...
зҷҫеәҰ google жҗңзҙўеј•ж“Һ жҗңзҙўеј•ж“ҺеҲҶжһҗ pptж–ҮжЎЈ
дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 03-зҪ‘з»ңзҲ¬иҷ«пјҲе…ұ27йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 04-жӯЈеҲҷиЎЁиҫҫејҸпјҲе…ұ13йЎөпјү.ppt дҪҝз”ЁC sharpејҖеҸ‘жҗңзҙўеј•ж“Һ C#жҗңзҙўеј•ж“ҺејҖеҸ‘е®һжҲҳ 05-...
дәәе·ҘжҷәиғҪ-жҗңзҙўеј•ж“Һ
tableauеҸҜи§ҶеҢ–еҲҶжһҗ-жЎҲдҫӢйӣҶй”Ұ-и®ҫе®ҡж јејҸ移йҷӨж–Үжң¬з¬Ұ
е…Ёд№ҰеҲҶдёүзҜҮе…ұ13з« еҶ…е®№пјҢд»Һеҹәжң¬е·ҘдҪңеҺҹзҗҶжҰӮиҝ°ејҖе§ӢпјҢеҲ°дёҖдёӘе°ҸеһӢз®ҖеҚ•жҗңзҙўеј•ж“Һе®һзҺ°зҡ„е…·дҪ“з»ҶиҠӮпјҢиҝӣиҖҢиҜҰз»Ҷи®Ёи®әдәҶеӨ§и§„жЁЎеҲҶеёғејҸжҗңзҙўеј•ж“Һзі»з»ҹзҡ„и®ҫи®ЎиҰҒзӮ№еҸҠе…¶е…ій”®жҠҖжңҜпјӣжңҖеҗҺйқўеҗ‘дё»йўҳе’ҢдёӘжҖ§еҢ–зҡ„WebдҝЎжҒҜжңҚеҠЎпјҢйҳҗиҝ°дәҶдёӯж–ҮзҪ‘йЎөиҮӘеҠЁ...
еҹәдәҺжҗңзӢ—зңҹе®һж—Ҙеҝ—ж•°жҚ®еҲҶжһҗзҡ„жҗңзҙўеј•ж“Һз”ЁжҲ·иЎҢдёәеҲҶжһҗ
зҪ‘з»ңжёёжҲҸ-з”ЁдәҺж–Үжң¬жҲ–зҪ‘з»ңеҶ…е®№еҲҶжһҗзҡ„еӨ§и§„жЁЎзү№еҫҒеҢ№й…Қзҡ„ж–№жі•.zip
зӣ®ж ҮжЈҖжөӢжЁЎеһӢгҖҒжҷәиғҪдјҳеҢ–з®—жі•гҖҒзҘһз»ҸзҪ‘з»ңйў„жөӢгҖҒдҝЎеҸ·еӨ„зҗҶгҖҒе…ғиғһиҮӘеҠЁжңәгҖҒеӣҫеғҸеӨ„зҗҶгҖҒжҷәиғҪжҺ§еҲ¶гҖҒи·Ҝеҫ„规еҲ’гҖҒж— дәәжңәзӯүеӨҡз§ҚйўҶеҹҹзҡ„з®—жі•д»ҝзңҹе®һйӘҢпјҢжӣҙеӨҡжәҗз ҒпјҢиҜ·дёҠеҚҡдё»дё»йЎөжҗңзҙўгҖӮ ---------------------------------------------...